
こんにちは、CTO室の毛利です。
前回の記事では、CVPR2019で発表されたAnchor系の物体検出の論文を紹介しました。
今回は、CVPR2019の物体検出の論文の中で、Heatmap系(Anchor-free系)の手法を紹介したいと思います。
- H. Law et al., "CornerNet: Detecting Objects as Paired Keypoints" (2018)
- X. Zhou et al., "ExtremeNet: Bottom-Up Object Detection by Grouping Extreme and Center Points" (2019)
- C. Zhu et al., "FSAF: Feature Selective Anchor-Free Module for Single-Shot Object Detection" (2019)
- 参考文献
H. Law et al., "CornerNet: Detecting Objects as Paired Keypoints" (2018)
- ECCV2018で発表されたHeatmap系(Anchor-free系)の火付け役(Heatmap系の厳密な初出ではない)
- CVPR2019の論文ではないが、CornerNetを紹介することでHeatmap系のreviewとする
モチベーション
- Bottom-up方式のpose estimation [A. Newell et al., (2016)] にインスパイアされた。
- Bottom-up式のpose estimationはjoint detectionとそのグループ化からなる。
- 物体検出も矩形の左上と右下の検出と、そのグループ化の問題とみなせるのでそのまま応用できる。
- Anchorを使うのを辞めたい
- Anchorの数が多いので、前景・背景のインバランス・hyper parameters(Anchorサイズやアスペクト比)が多くなる などの問題を引き起こす。
- Anchorのように矩形を一気に指定しようとすると、左上・右下の座標を指定する必要があるので、候補が
になる。一方、cornerなら候補は
と少くて済む。その代わりにグループ化が必要になる。
手法概要
- Heatmapで、Corner(矩形の左上と右下)検出
- Cornerのグループ化に関する情報も同時に推論させる (associative embedding)
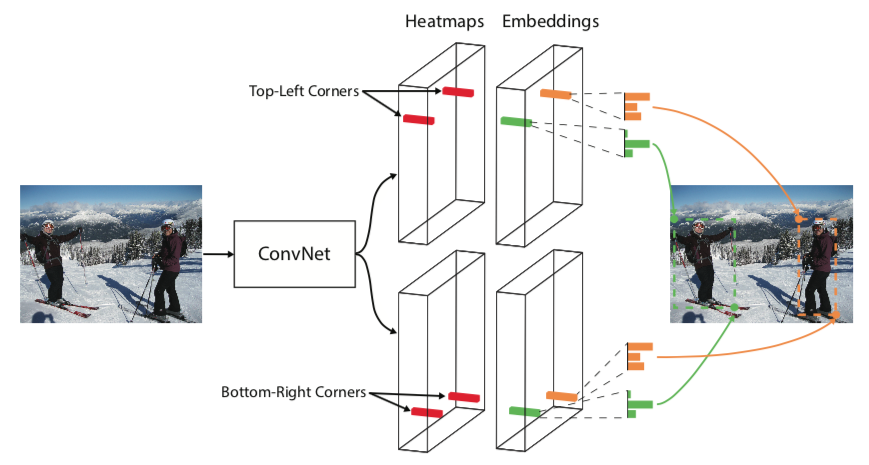
手法: Corner検出
- Cornerの場所(矩形の左上と右下)をクラスごとにHeatmapとして出力させる
- Corner検出の出力は、特徴量解像度が
の時、C(クラス数)チャンネルのsigmoid
- 基本はSegmentationなどと同じだが、背景も含めたsoftmaxではなくsigmoidを使う。恐らく、違うクラスの物体のCornerが重複している状況などがあるため
- Corner検出の出力は、特徴量解像度が
- GTは点だと前景・背景インバランスが問題になるので、GTの場所をピークとしたガウシアンにする。
- そのGT heatmapをbinary cross entropy lossで学習させる。ただし、インバランス対策としてfocal lossを使う。
手法: グループ化 (associative embedding)
- 各cornerのグループに関する情報
(1次元ベクトル, embeddingと呼ぶ)を出力させる
- 同じインスタンスに属するcornerの
手法: sub-pixel regression
- Corner検出の解像度(Heatmapの解像度)は、入力画像の解像度より小さいので、そのままだと位置精度が荒くなってしまう
- 入力画像の解像度の位置精度にするために、Corner検出の解像度でsub-pixel regressionする
- Lossはsmooth
- Lossはsmooth
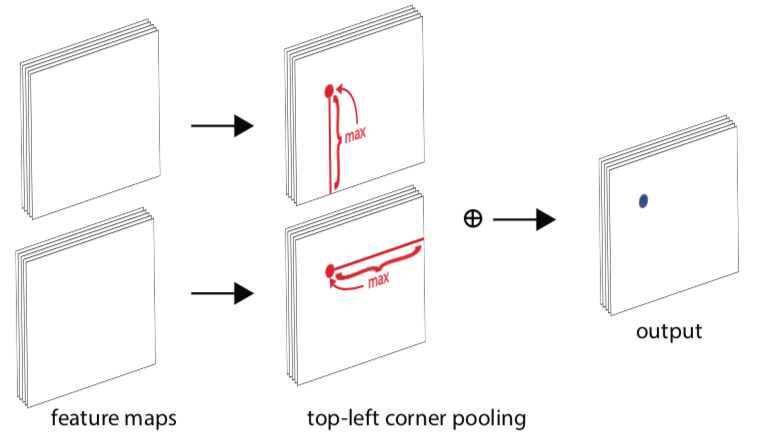
手法: CornerPooling
- 下図のように、Cornerには物体はなく何も特徴がないことが多い
- 物体境界は、左上のCornerなら、Cornerから右方向や下方向に存在する

- そこで、下図のようなPoolingをすることで、物体境界の情報をCornerに伝搬させる。
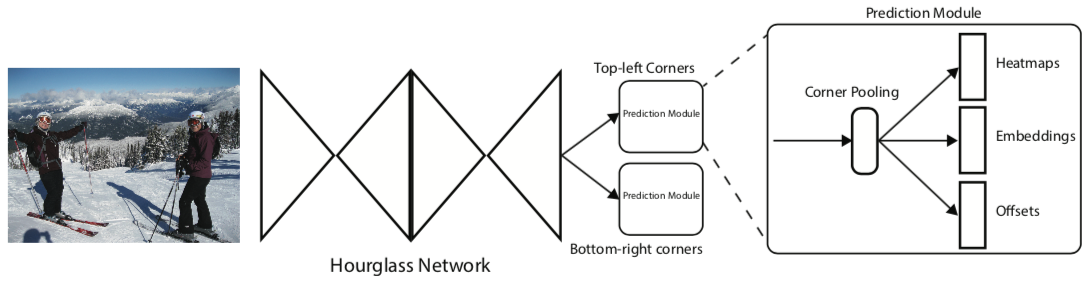
手法: 全体図
- BackboneはHourglass NetworkというEncorder-Decorder構造をしたものを使用
- CornerPoolingが左上と右下で違うので、Hourglass Networkの出力を左上用と右下用のモジュールで分離
感想・コメント
- 基本はpose estimation [A. Newell et al., (2016)]からの流用なので、本質的に新しい部分はCornerPoolingだけだが、それを物体検出に使ったのはコロンブスの卵だったのかも知れない
- Heatmap系の初出ではないが、火付け役になったのは確か
X. Zhou et al., "ExtremeNet: Bottom-Up Object Detection by Grouping Extreme and Center Points" (2019)
- Cornerではなく、Extreme pointで矩形境界を検出するHeatmap系の方法を提案
モチベーション
- 矩形は物体の位置のよい表現方法ではない
- 物体は画像に平行になっているとは限らない
- 矩形の中には背景が多数含まれる
- 矩形のコーナーには物体はないことが多い

手法: 概要
- cornerではなく、extreme point(物体の上下左右に一番端の点)をheatmapで検出する
- グループ化はextreme pointとcenter pointの位置関係で行う
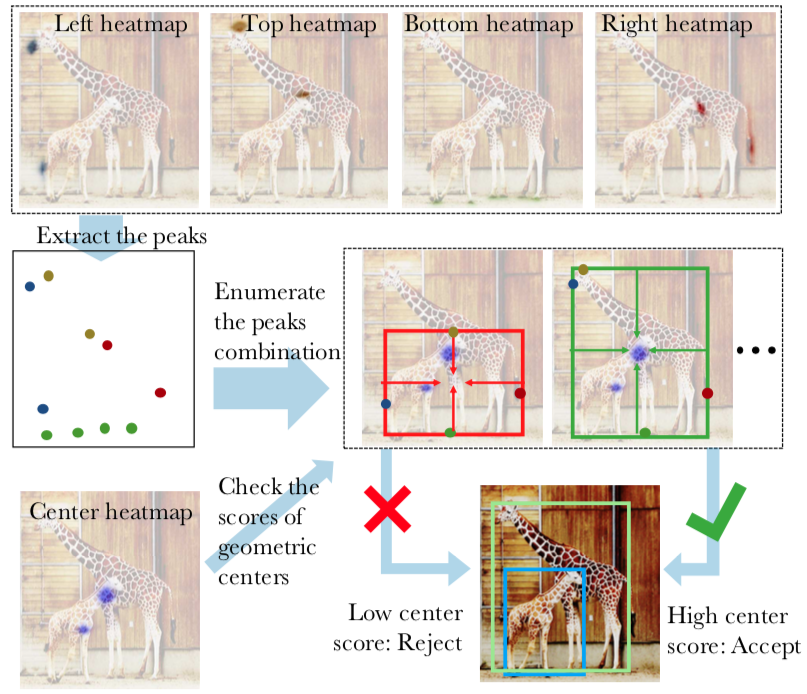
手法: Keypoint Detection
- 物体検出のAnnotationをするのに、矩形をAnnotationするより、Extreme pointsをAnnotationした方が早いし簡単 [Papadopoulos et al. (2017)]
- 例えば、人の検出だったら、top-most pointは頭だし、飛行機のbottom-mostは車輪と、その場所に特徴があるので簡単 (一方、cornerには必ずしも物体がない)
- 人間にとってそうなら、機械にとってもそうだと期待できる
- Extreme pointsから矩形は作れるが、矩形からExtreme pointは作れない(Extreme pointの方が情報量が多い)。
- Extreme points(上下左右の4つ)とCenter point(物体の中心)をheatmapで検出する
- Center pointはグループ化に使う
- 矩形からExtreme pointsは得られないので、矩形のAnnotationでは学習できないので注意(Center pointはExtreme pointsから計算できるので、別途Annotationは必要ない)
手法: Network構造
- 基本はCornerNetと同じで、BackboneはHourglassNet、HeatmapはGTをガウシアンで広げてFocal lossで学習、sub-pixel regressionは
-lossで。
- ネットワークの出力は、Heatmapが5(Extreme+Center points)xクラス数Cで、Offset(sub-pixel regression)が4(for each extreme points)x2(x,y)のチャンネル数になる
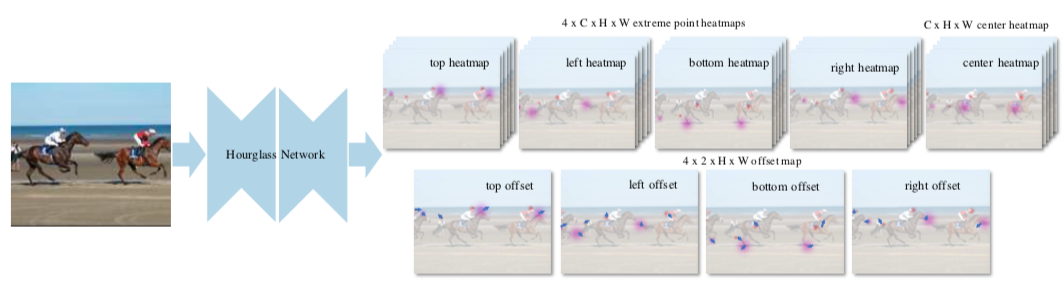
手法: Center grouping
- ピーク抽出: heatmap推論結果から3x3 window内で最大、かつ、しきい値0.1を超えてる点を検出されたextreme pointとする
- グループ化: 4つのExtreme pointsから計算した中心の位置が、center heatmapでしきい値0.1以上なら検出とする
- 検出された物体のスコアは、ExtremeとCenterのHeatmapの5つの平均
- 4つのExtreme pointsの組み合わせは
あるが、
が大きくないのでbrute forceでも問題ない(
手法: 後処理
- Ghost box suppression: このグループ化のやり方だと、3つの物体が直線上に等間隔に並んでいた場合にFalse positiveになる。矩形に含まれるheatmapのスコアの合計が、矩形のスコアの3倍より大きい時には、その矩形のスコアを1/2する。
- Edge Aggregation: extreme pointsは必ずしもユニークでない(物体のエッジがextreme pointsになる車の上部とか)。ピークが鋭くならないため問題になる。ピークの周りの領域のスコアも重み付きで加算することで、スコアを上げる。
実験・感想
- MS COCOのInstance SegmentationのデータからExtreme pointのAnnotationは作成
- Extreme pointを使うという設定で、Center groupingでなく、CornerNetと同様のAssociative embeddingを使ったら精度が下がる
- CornerNetからあまり精度が上がってない... (multi-scaleテストだと勝っているが、single-scaleテストだと負けている)
- CornerNetと比較して学習時間は短くなったみたいだが、精度的に変わらないので微妙な気がする
C. Zhu et al., "FSAF: Feature Selective Anchor-Free Module for Single-Shot Object Detection" (2019)
モチベーション
- Anchor系の手法では色々な大きさの物体に対応するために、複数の解像度の特徴量を使っている
- 既存手法では、Anchorの種類(大きさ・アスペクト比)と、そのAnchorが利用する特徴量解像度の関係はHeuristicに決めているが、それが最適とは限らない。Anchorの種類で使う特徴量を決めるが、一般にはインスタンスごとに最適な特徴量が違う可能性もある。
手法概要
- one-stageのAnchor系の手法のHeadだけ修正して、Heatmap系(Anchor-free branch)にする
- 学習時に使う特徴量の解像度は、動的に決める(feature selection)
- Anchor系のHeadと、Heatmap系のHeadを同時に使うことも可能
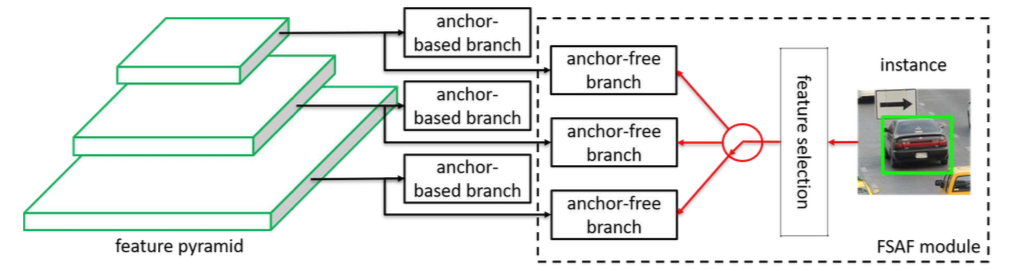
手法: ネットワーク構造
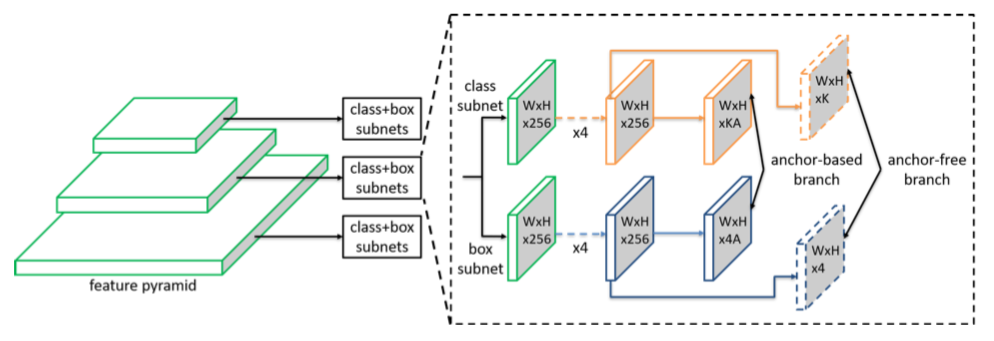
- Anchor系のネットワーク構造を基に、SubNetworkの部分だけ変更してHeatmap系にする。
- AnchorヘッドからAnchor-freeのヘッドへの変更は、classificationとregressionのSubNetworkの一番最後の畳み込みだけ変更して、出力のチャンネル数を
から
にする(
はクラス数で、
はAnchor数)
- マルチタスクの時にやるように、Anchor系とHeadmap系を同時に学習・推論させることが可能
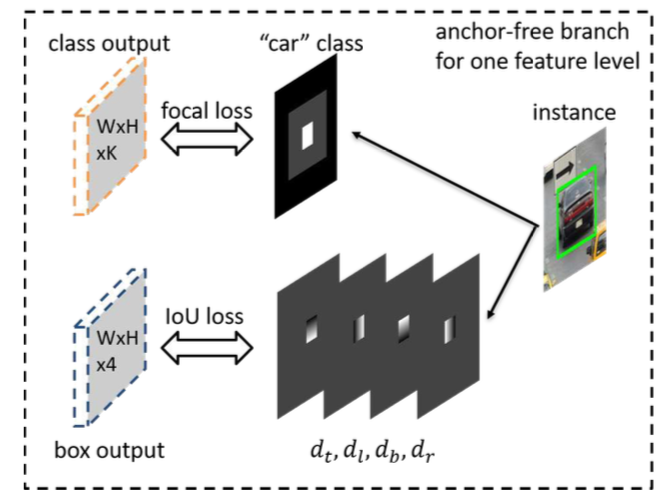
手法: Loss
- 入力解像度での矩形を、各特徴量の解像度の矩形にリサイズする:
@ level-
特徴量
- classificationは、矩形の中心付近をHeatmapで推論させる: Focal loss
- effective 矩形: GTの矩形の20%の大きさ(下図の白色領域)。学習時にHeatmapを前景扱い。
- ignore 矩形: GTの矩形の50%の大きさ(下図の灰色領域)。学習時にLossに反映させない。
- 上のどちらでもない(図の黒色領域)は背景扱い
- regression: 該当Pixelから上下左右がどれくらい離れているかを推論: IoU loss (effective領域以外はLossに反映させない)
手法: Feature selection
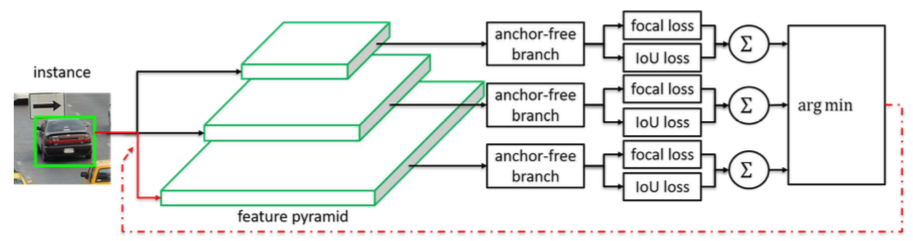
- 各level(特徴量解像度)でLossを計算して、一番小さくなるlevelだけ学習させる:
ここで、はインスタンス
- 現状で一番いいlevelだけを更に学習させるイメージ
- 比較として(インスタンスの大きさから)Heuristicに使うlevelを決める方法も試している
- 推論時は全てのlevelで推論させてNMSする(Lossが一番いいlevelの検出が自然に選ばれる)
実験
- Heatmap Head + Heuristic feature selectionでは、Anchor Headより悪化
- Heatmap Head + Online feature selectionでは、Anchor Headより少し向上
- (Heatmap Head + Online feature selection) + Anchor Headが最強
- 提案手法は、定性的には小さい物体や細長い物体に強いっぽい
感想・コメント
- Anchor系とHeatmap系の対比が分かりやすく、違いがよく理解できた
- Heatmap系は本質的にはAnchor系の一種で、Anchorの種類を1つだけにした極限と捉えることができそう
- Heatmap系は単一の解像度の特徴量だけが使われてきたが、Anchor系みたいに複数の特徴量解像度を使ったのは、この論文がたぶん初
- これまでAnchor系とHeatmap系の比較は違うBackboneだったりして平等な比較がなかったが、純粋な比較になっていてHeatmap系の優位性を示唆している
- ただし、Heuristic feature selectionでは精度が悪いので、純粋にHeatmap系がいいのか、特徴量の選び方のおかげなのかは不明(Anchor系でも、動的に特徴量を選べない?)
参考文献
- [Law+(2019)] H. Law(University of Michigan) et al., "CornerNet: Detecting Objects as Paired Keypoints"
- [Zhou+(2019)] X. Zhou et al., "ExtremeNet: Bottom-Up Object Detection by Grouping Extreme and Center Points" (2019)
- [Zhu+(2019)] C. Zhu et al., "FSAF: Feature Selective Anchor-Free Module for Single-Shot Object Detection" (2019)