本記事は、2021年のインターンシップで勤務した高橋直暉さんによる寄稿です。
はじめまして。株式会社モルフォでインターンをしていた高橋です。私のインターンシップでは、画像生成タスクの一つであるImage Inpaintingに取り組みました。このタスクは、毎年新しい手法が提案されており、近年では深層学習を導入した手法が主流です。今回は、シンプルで軽量なエッジ情報を用いたImage Inpainting手法[1]の改良に取り組みました。この記事では、インターンシップを通して得られた成果を紹介していきたいと思います。
Image Inpaintingとは
Image Inpainitngとは、図1のような白いマスク領域をもっともらしく埋め込むタスクです。この技術は、望まないオブジェクトの削除や欠損画像の復元を目的としたアプリケーションに利用されます。近年の手法では、マスク領域が大きくても多様な出力(multi-modal)や実写(photo-realistic)のような画像を生成します。さらに、漫画[2]、ユーザーガイド[3]、動画[4]など多様なドメインにも応用されています。しかし、複雑な構造でマスク領域が大きい画像では、生成結果にアーティファクトやボヤけが現れます。よって、さらなる精度の向上が望まれるタスクとなっています。

既存手法
近年の画像生成タスクでは、深層学習を用いた手法が多く提案されています。Image Inpaintingでも、深層学習を用いることで学習データの分布からマスク領域内部を推測します。このタスクの課題は、画像全体の構造を保ちながら、詳細なテクスチャを生成することです。そのため、近年の手法では、構造を理解するネットワークと詳細なテクスチャを生成する複数ネットワークで構成されるend-to-endな手法が多いです。ここでは、本インターンシップでベースモデルとして使用した手法を説明したいと思います。
EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning [CVPR2019 Nazari+]
この手法は、図2のように2つのGANs(Generative Adversarial Network)ネットワーク[5]から構成されます。一つ目のネットワークでは、マスク化されたエッジ画像に対してInpaintingを行います。このネットワークでは、高周波成分であるエッジの学習に注力することで、画像全体の構造を保っています。2つ目のGANネットワーク
では、復元されたエッジ画像から最終的な画像を生成します。このネットワークで詳細なテクスチャの生成を試みています。このように、2つのネットワークを使用することで構造を保ったまま、詳細なテクスチャの生成を実現しています。
図2EdgeConnectのネットワーク全体図 - [1] Figure 2より引用
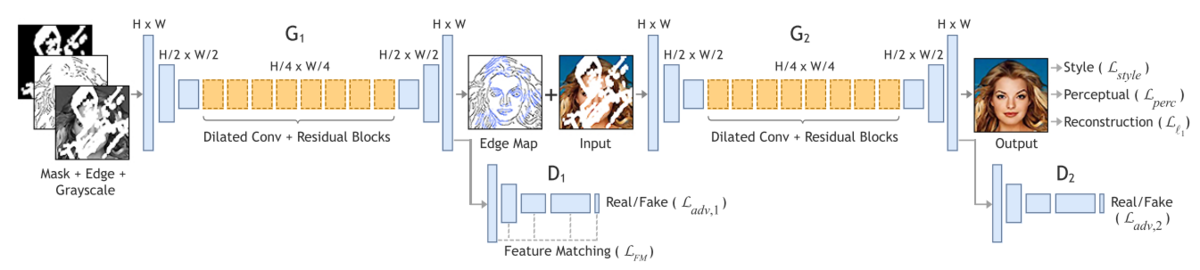
提案手法
既存手法では、マスクが大きい場合にエッジのInpaintingを失敗する傾向があり、最終的な出力画像はボヤけたりアーティファクトが目立ちました。そこで、本インターンシップでは、1つ目のエッジInpaintingの改良に取り組みました。ここでは、インターンシップ中に提案した手法をいくつか説明します。
エッジマップの検討
既存手法では、1つ目のネットワークでCannyエッジをInpaintingすることで画像の構造を保持しています。しかし、図3(b) のCannyエッジでは、顎や目 のエッジが抽出できていないことが確認されます。そこで、私はDoG(Difference of Gaussians)とXDoG(eXtended Difference of Gaussians)[6]を使用しました。DoGは、カーネルサイズが異なるフィルタで差分を取ることで、ノイズに強いエッジ抽出を可能としています。XDoGでは、DoGにシャープ化と閾値処理をかけることでインクイラストのような画像を生成します。下図 (c, d) の例では、Cannyでは抽出できなかった顎や目のエッジがDoGとXDoGでは抽出できていることが確認できます。また、XDoGでは閾値により減色化された連続的な値を持っているため、影の抽出もできていることが確認できます。

ガンマ補正の検討
今回の実験で使用するParis street view[8]では、コントラストの低い画像が多く含まれています。そのため、図4(a)のようなコントラストの低い画像では、DoGのエッジ抽出がうまく働かないことがあります。そこで、エッジ抽出時にガンマ補正を掛けることで、低コントラスト画像でもエッジが抽出できるようにしました。図4(b, c)より、ガンマ補正によってDoGのエッジ抽出が改善され、XDoG (d, e)でも変化が確認できます。

ロスの検討
マスクが大きい場合、Inpaintingされたエッジでは鱗模様やボヤけが生成されます。これを改善するためにBinarization lossとTotal variation lossを追加しました。Binarization lossは、0か1の画素値を高く評価する損失関数であり、エッジ付近の学習を効率化させます。Total variation lossは、スタイル変換[9]などで使用されている画像の滑らかさを評価する損失関数です。以上の2つの損失関数を既存手法に加えてモデルを学習させました。
実験
実験では、CelebA[10]とParis street view[8]のデータセットを用いてモデルを学習させました。CelebAは、著名人の顔画像を集めたデータセットです。Paris street viewは、Google Street Viewから取得したパリの街並みを集めたデータセットです。それぞれからランダムに取得した1万枚の画像を40エポックで学習させました。
精度評価では、PSNR、SSIM、FID、LPIPSの4つを用いました。PSNRは、画素値の変化を評価する古典的な評価手法の一つですが、一つの画素値が大きく異なるだけで全体の評価が悪く判定されます。そのため、ウィンドウごとに画素値やコントラストを評価するSSIMも使用しています。また、近年の深層学習の発展に伴い、深層学習の大規模ネットワークを用いた評価手法であるFIDとSSIMも使用しています。FIDではInceptionモデルの中間ベクトルから画像集合の分布間距離によって評価され、LPIPSではImageNetの中間特徴量から画像間の視覚的類似度を評価します。
本セクションでは、モデルの出力画像と評価結果を元に、提案手法の有効性を検証していきたいと思います。
エッジの推定精度の比較
人物の顔画像
表1は、各エッジを用いて生成した結果の評価値を示しています。ここで、青色は最も悪い結果を示し、赤色は最も良い結果を示しています。表より、全てのマスクサイズにおいて、提案手法のDoGとXDoGが既存手法のCannyを上回っていることが確認できます。
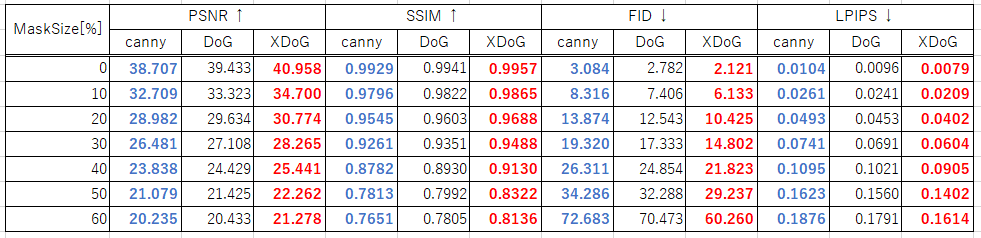
図5のグラフは、マスクサイズにおけるFIDとLPIPSの変化を示しています。図より、マスクサイズが大きくなると、XDoGと他のエッジの精度差が広がっていることが確認できます。これは、XDoGでは中間特徴の類似性が優れていることを示しているため、画像の構造保持として、より機能していると考えられます。
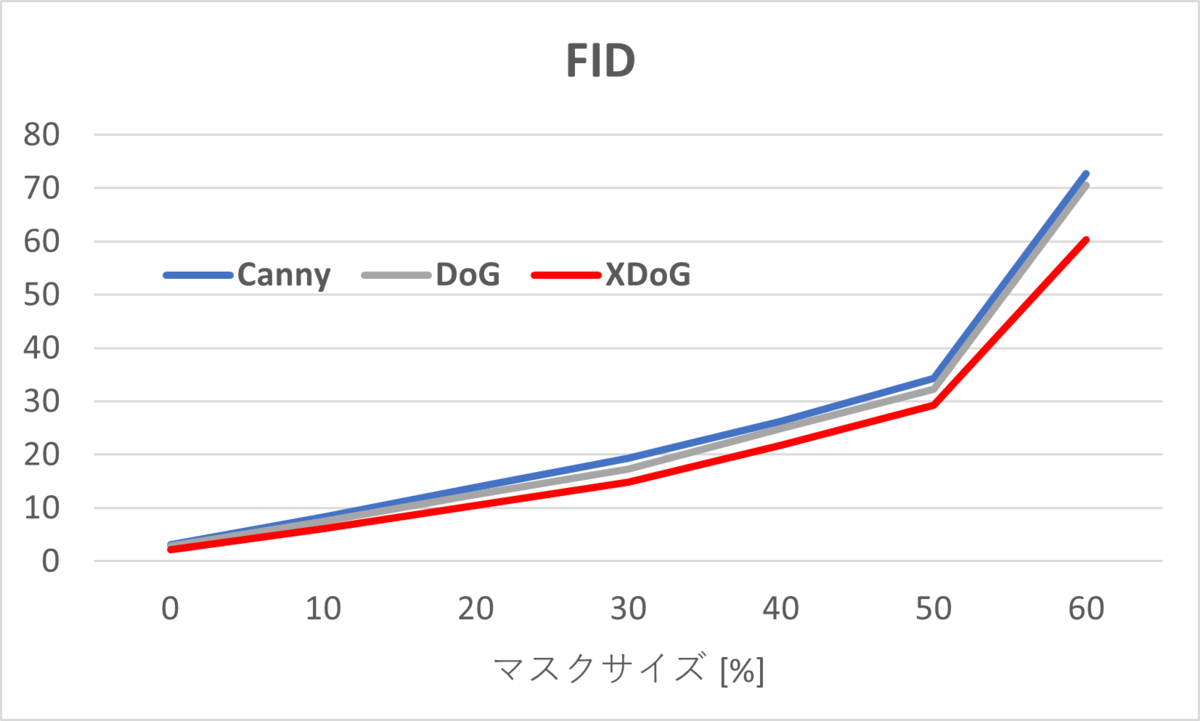
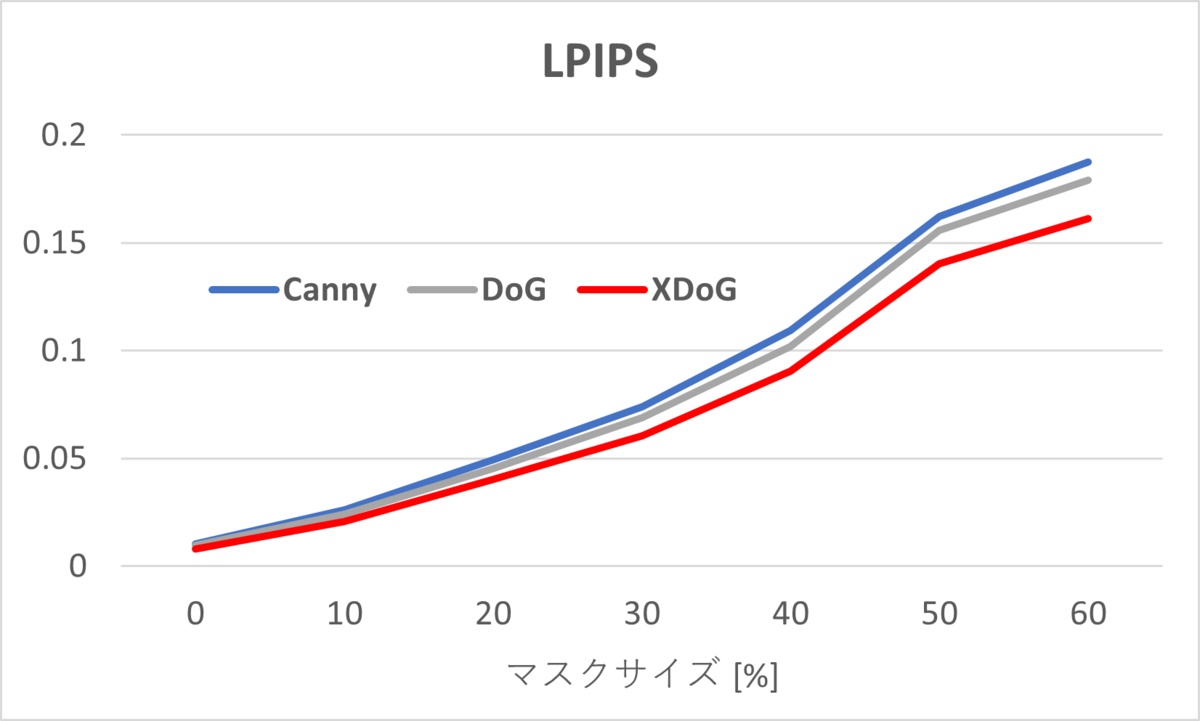
図6は各エッジマップにおけるマスクサイズが30-50%の生成結果を示しています。既存手法のCannyでは、目の崩れが確認されます が、DoGとXDoGではエッジが効いた画像が生成されています。また、マスクサイズが50%の時は、CannyとDoGでは顔の輪郭が崩れていますが、 XDoGでは保たれています。

風景画像
表2の結果より、XDoGが最も優れたエッジマップであることが確認できます。ただし、データセットの性質上、CelebAに比べて全体的に精度が悪いことが確認されます。これは画像対象物が多様で複雑であることが要因として考えられます。
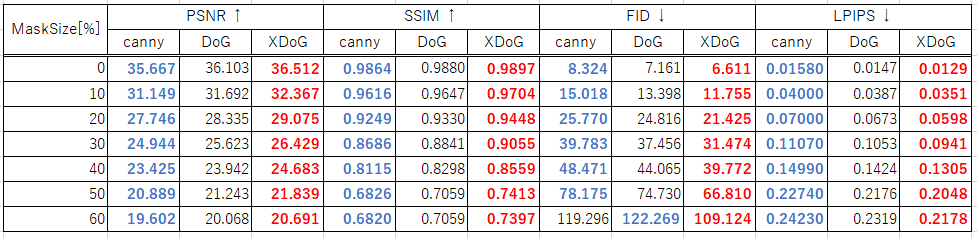
図7は、マスクサイズが10-30%の生成結果を示しています。他のエッジマップに比べてXDoGでは、エッジ がよりはっきりと生成されていることが確認されます。

以上より、複数のデータセットにおいて、XDoGを使うことで精度の向上を確認できました。
ガンマ補正の検証
表3は、ガンマ補正有無のDoGとXDoGの精度結果を示しています。ここで、表の赤文字は勝っている結果を示しています。表3より、DoGにはガンマ補正が有効に作用し、XDoGには逆効果だったと確認できます。これは、ガンマ補正によってDoGのエッジ抽出が明らかに向上していましたが、XDoGのエッジ抽出は元から機能していたため良い影響を与えなかったと考えられます。

図8は、ガンマ補正有無のDoGを用いた結果です。通常のDoGでは建物や窓のエッジが抽出できず復元結果がボヤけていますが、ガンマ補正をかけることでエッジが効いてマスク跡が目立たない画像が生成できています。

ロスの追加
表4は、XDoGを用いた既存手法(Vanila)に、Binarization Loss(+Bi)、Total Variation Loss(+TV)、その両方(+TV+Bi)を加えた4手法を比較しています。ここで、表の赤文字は最も良い結果を示しています。表より、精度差は少なく、精度の向上は確認できませんでした。学習曲線が収束していなかったので、学習時に損失関数がうまく働かなかったと考えられます。

以上より、上手く行った手法と上手くいかなかった手法がありました。今後は、ヒストグラム平滑化によるコントラスト補正やロスの重みを変えて精度が向上するか確認してみたいと思います。
デモ動画
GitHub - Kohey1480/inpaint-appを参考にデモ用アプリケーション上で実験を行いました。選択タブでエッジの種類とデータセットを選択できるようになっています。動画の前半は、FFHQ[7]の画像とXDoGを用いて、目のInpaintingをしています。後半部分は、スマホで撮影した写真の一部をマスクしています。
続いてのデモ動画では、街の風景をスマホで撮影した画像を用いています。マスク境界付近にボヤけが確認されますが、オブジェクトの削除に成功しています。このモデルは少ない画像枚数で学習されたため、ImageNetなどの大規模データセットで事前学習をすることで精度の向上が期待できます。
感想
今回のインターンシップは、東京で緊急事態宣言が発令されたため、大部分をオンライン上で行いました。幸運なことに1週目は出社が出来たので、メンター以外の社員さんと交流して、モルフォでの働き方の話を聞くことができました。また、社内の報告会や勉強会にも参加させて頂けたので、具体的な事業内容や最新の論文などを知れて勉強になりました。最初は成果が出るか不安でしたが、メンターの献身的なサポートのおかげで既存手法よりも精度が向上したので、非常に充実したインターンが送れたと思います。 最後に、本インターンを行うにあたって、研究のアドバイスやオンラインの環境構築をしてくださった株式会社モルフォの社員さんに感謝申し上げます。
参考文献
[1] Nazeri, Kamyar and Ng, Eric and Joseph, Tony and Qureshi, Faisal Z and Ebrahimi, Mehran. EdgeConnect: Structure Guided Image Inpainting using Edge Prediction. ICCV2019
[2] Minshan Xie and Menghan Xia and Xueting Liu and Chengze Li and Tien-Tsin Wong. Seamless Manga Inpainting with Semantics Awareness. SIGGRAPH 2021
[3] Jo, Youngjoo and Park, Jongyoul. SC-FEGAN: Face Editing Generative Adversarial Network With User's Sketch and Color. ICCV2019
[4] Liao, Miao and Lu, Feixiang and Zhou, Dingfu and Zhang, Sibo and Li, Wei and Yang, Ruigang. DVI: Depth Guided Video Inpainting for Autonomous Driving. ECCV2020
[5] Goodfellow, Ian and Pouget-Abadie, Jean and Mirza, Mehdi and Xu, Bing and Warde-Farley, David and Ozair, Sherjil and Courville, Aaron and Bengio, Yoshua, Generative adversarial nets. In Advances in neural information processing systems. 2014
[6] Winnemöller, Holger and Kyprianidis, Jan Eric and Olsen, Sven C. Xdog: an extended difference-of-gaussians compendium including advanced image stylization. Computers & Graphics, 36(6). 740--753. 2012
[7] Karras, Tero, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. CVPR2019
[8] Pathak, Deepak and Krahenbuhl, Philipp and Donahue, Jeff and Darrell, Trevor and Efros, Alexei. Context Encoders: Feature Learning by Inpainting. CVPR2016
[9] Mahendran, Aravindh and Vedaldi, Andrea. Understanding deep image representations by inverting them. CVPR2015
[10] Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou. Deep Learning Face Attributes in the Wild. ICCV2015