モルフォでは最先端の画像処理・機械学習に関する研究のキャッチアップのため、国内外問わず毎年各種学会に技術系の社員を派遣しています。今回は機械学習の国際会議「International Conference on Machine Learning 2021(ICML 2021)」に長山と、同じくCTO室リサーチャーの鈴木・中川で参加しました。本投稿では、はじめに学会の概要について説明し、次に私が注目した論文3本を紹介します。
ICML 2021 概要
ICML(International Conference on Machine Learning)は機械学習に関する総合的な国際会議であり、トップカンファレンスの一つとして認知されています。毎年7月頃に開催され、世界各国の研究機関や企業から、学術研究者やエンジニア、起業家などの様々なバックグラウンドを持つ参加者が一堂に会し、機械学習のあらゆる側面における最先端の研究成果を発表しています。第38回となる今年度はオーストリアのウィーンで開催予定でしたが、世界的なCOVID-19の流行の影響により完全バーチャル開催となりました。
[3] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” in International Conference on Learning Representations (ICLR), 2015, [Online]. Available: https://arxiv.org/abs/1412.6572
[4] K. Leino, Z. Wang, and M. Fredrikson, "Globally-Robust Neural Networks," in International Conference on Machine Learning (ICML), 2021, pp. 6212–6222 [Online]. Available: https://proceedings.mlr.press/v139/leino21a.html
[5] Y. Tian, X. Chen, and S. Ganguli, “[Presentation] Understanding self-supervised learning dynamics without contrastive pairs,” in International Conference on Machine Learning (ICML), 2021, [Online]. Available: https://icml.cc/media/icml-2021/Slides/10403.pdf
[6] J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. H. Richemond, E. Buchatskaya, C. Doersch, B. A. Pires, Z. D. Guo, M. G. Azar, B. Piot, K. Kavukcuoglu, R. Munos, and M. Valko, "Bootstrap your own latent: A new approach to self-supervised Learning," in 34th Conference on Neural Information Processing Systems (NeurIPS 2020), 2020, [Online]. Available: https://arxiv.org/abs/2006.07733
[7] X. Chen, and K. He, "Exploring Simple Siamese Representation Learning," in IEEE conference on computer vision and pattern recognition (CVPR), 2021, [Online]. Available: https://arxiv.org/abs/2011.10566
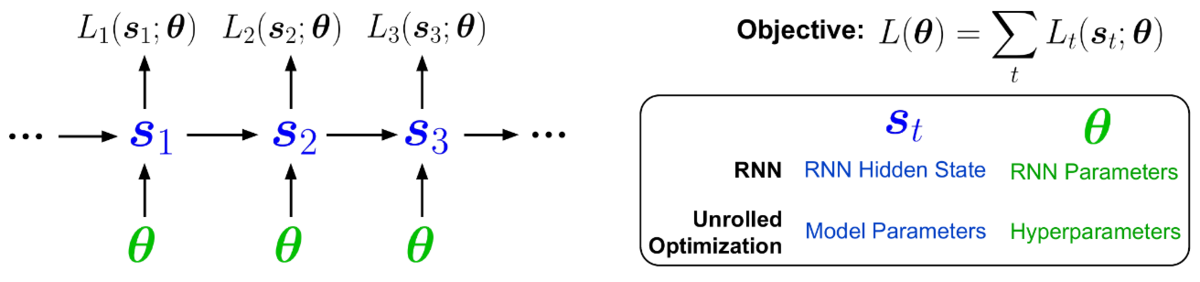
[8] P. Vicol, L. Metz, and J. Sohl-Dickstein, “Unbiased Gradient Estimation in Unrolled Computation Graphs with Persistent Evolution Strategies,” in International Conference on Machine Learning (ICML), 2021, pp. 10553–10563 [Online]. Available: http://proceedings.mlr.press/v139/vicol21a.html

が小さい)かつ正しく分類されたデータの割合。↩
におけるパラメータを
、目的関数を
としています。ここで
です。状態変数
は表記を省略しています。↩