こんにちは、CTO室リサーチャーの長山と申します。
モルフォでは毎週金曜日に持ち回りで論文紹介等を行うJournal Clubという取り組みを行っています。 今回は、私がその場で発表したSchrödinger Bridge(シュレーディンガー橋; SB)という確率論的生成モデルスキームの解説スライドを公開いたします。
Stable DiffusionやMidjourneyに代表されるような画像生成AI手法は、ここ一年間で目覚ましい発展を遂げたことは記憶に新しいと思います。 その原動力となった基礎技術の一つが拡散モデル(Diffusion Models)です。 拡散モデルとは、データからノイズへと徐々に崩壊するような過程を学習し、その逆過程(すなわちノイズ除去)をシミュレーションすることで目標のデータを創り出すような手法と説明することができます(図1)。 高い生成品質かつ安定した学習を実現できることから、拡散モデルは画像生成AIにおける以前の主流であった敵対的生成ネットワーク(Generative Adversarial Networks; GANs)を現在進行系で置き換えつつあります。
図1: 拡散モデルの崩壊・生成過程(引用: arXiv:2006.11239)

画像生成AIという名称を聞くと、入力したお題に沿った絵をAIが生み出す「お絵描きAI」を一番に想像される方が多いと思いますが、それ以外にImage-to-Image(画像から画像への変換)へも応用されています。 Image-to-Imageの例としては、画像中の不要な対象を違和感なく消すようなタスクであるインペインティングが特に印象的です。 他にも、画像サイズの拡大(超解像)や画像をくっきりさせる処理(ボケ除去)などもImage-to-Imageの一種といえます。 もちろん、拡散モデルを応用したImage-to-Image手法も数多く提案されていて、様々なタスクにおいてSOTAに匹敵する性能が報告されています。
しかしながら、拡散モデルを使ったImage-to-Imageと謳うほぼ全ての手法は、実は厳密には画像から画像へと直接的に変換しているわけではありません。 ノイズから画像を生成するモデルにプロンプト(お題のテキスト)で条件付けした手法がお絵描きAIであるのと同様に、入力画像で条件付けしたときのモデルのことを、拡散モデルの文脈では一般にImage-to-Imageと呼んでいます(図2左)。

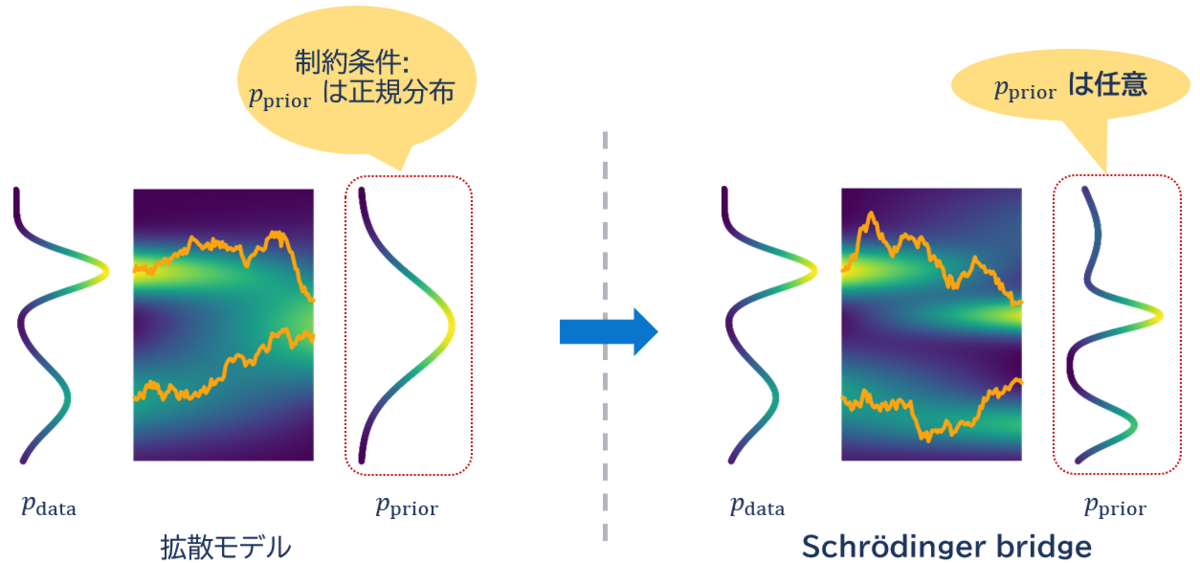
ここで、"原画像"と"ノイズ"の2要素を使って生成するのは一見すると無駄が多そうなので、「"原画像"だけで拡散モデルと同じようなことはできないのか?」という素朴な疑問が湧くのは自然なことでしょう。 ですが、拡散モデルという枠組みの上ではノイズを利用することが本質的なので、これを変更することは容易ではありません。
このような問いに対する答えの一つがSchrödinger Bridge(SB)と呼ばれる生成モデルスキームです。 結論から述べると、SBはノイズの制約を取り払った拡散モデルとみなすことができ、直接的なImage-to-Imageを構成することができます(図3)。
SBの詳細については以下のスライドをご覧ください。 このスライドの前半では、いわゆる "拡散モデル" の時間連続化に相当するスコアベース生成モデル(Score-based Generative Models; SGMs)の基礎事項について簡潔に述べています。 そしてスライドの後半では、SGMの一般化を動機としてSBモデルを導入し、最適輸送(Optimal Transport; OT)との関係性ならびに機械学習分野で最近よく用いられる形式の定式化について解説しています。
なお、今回はSBの基本的な性質に絞って説明を行ったため、具体的な学習方法(損失関数の設計方法など)や応用手法については触れていません。 これらにつきましては、今後公開する Part II 以降にて解説する予定です。