本記事は、2022年度の実務訓練で勤務した高橋快斗さんによる寄稿です。
はじめに
はじめまして。2023年の1月から2月にかけて株式会社モルフォで実務訓練を行っていた豊橋技術科学大学の高橋です。 本実務訓練では、昨今話題のText-to-Image技術を応用したネイル画像生成アプリケーションを作成しました。このアプリケーションでは、ユーザーがネイルデザインを指定することで、自動的に画像を生成することができます。
生成画像
早速ですが、生成されたネイル画像は図1になります。

流行のデザインのネイル画像が生成できていることが確認できます。
更に、複数のデザインの特徴を併せ持った世界初のデザインのネイル画像も生成することができます。

下記では実務訓練で取り組んだ、このような画像を生成するアプリケーションの作成の過程を記載します。 是非ご覧ください。
テーマ決め
昨今、深層学習を利用した画像生成が流行しております。 具体的には、アニメ風の画像生成*1やパッケージデザイン*2やホイールデザインの画像生成*3などが実用化に至っております。 今回は、他に需要が見込まれる分野について調査した結果、まだ実用化されていないおしゃれなネイル画像の生成にテーマを設定しました。

Stable Diffusion
今回は学習済Stable Diffusion*4を画像生成モデルのベースとして用い、ネイル画像データによるファインチューニングを行いました。 このモデルを端的に言いますと、テキスト(プロンプト、文章)から画像を生成するモデルです。 ここではモデルの詳細な説明は割愛します。
データセット作成
ファインチューニングには、画像とキャプションのペアのデータセットが必要です。 そこで今回は、画像収集、テキスト認識、テキスト削除、キャプション付与の過程を経てデータセットを作成しました。
1. 画像収集
今回は、googleのCustom Search APIを用いて画像を収集しました。 このAPIを用いると、任意の用語を指定することでグーグル検索結果で得られる数百枚の画像を得ることができます。 検索したデザインの種類数は113枚、総画像枚数は4842枚です。 検索用語としては、「クリスマスネイル」「フレンチネイル」のように流行のネイルデザインの名前を入れました。 その後、低解像度の画像の除去をしました。
2. テキスト認識
画像内に文字が含まれているデータセットでファインチューニングを行うと、生成画像内に文字が生成されるという不都合が生じた為、テキスト削除を行いました。 テキストを削除するために、テキストをEasyOCR*5で認識しました。
3. テキスト削除
テキスト認識結果を元に、マスク画像を生成し、MAT*6を用いてテキストを削除しました。
4. キャプション付与
BLIP*7を用いて全ての画像それぞれに対して、キャプションを生成しました。
さらに、新たなネイルデザインの概念を学習させる意図で、キャプションの末尾に検索クエリを追記しました。

学習結果
上記で作成したデータセットでファインチューニングを行ったモデルにて生成した画像例が図5になります。

複数のデザインの特徴を併せ持つネイルの画像も生成することが可能となっております。

想定通り、学習画像内からテキストを削除することで、生成画像から余分な文字の出現を抑制することができました。

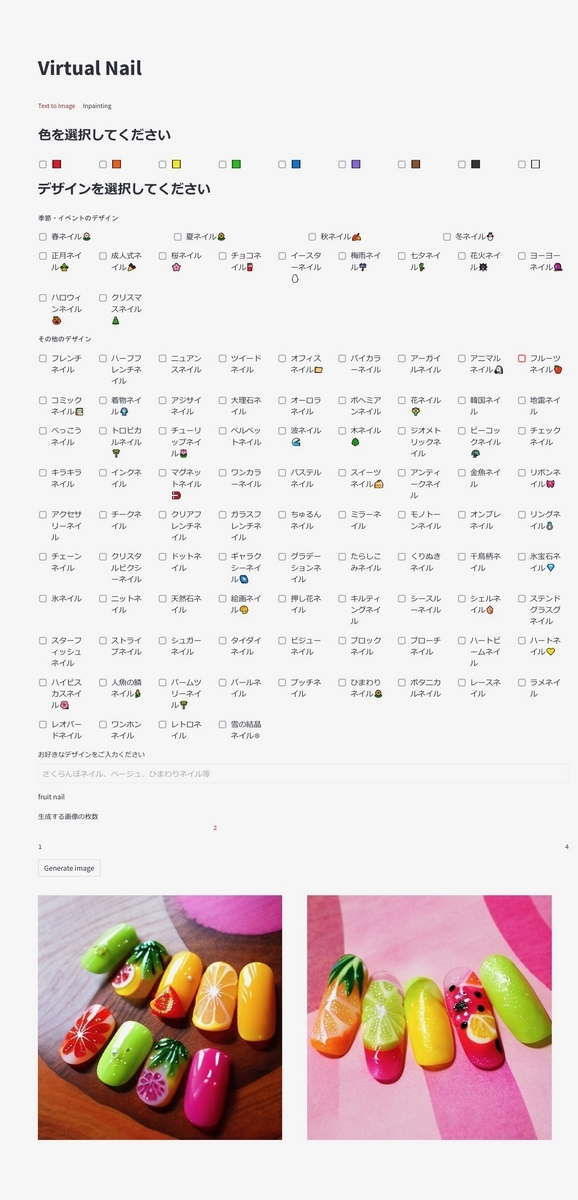
GUI
Streamlitを用いてGUIの作成を行いました。
チェックボックスにより、デザインの提案及び複数のデザインの選択ができ、テキストボックスによりユーザー独自のデザインの指定ができます。
社内での動作試験にあたり、セマフォを用いて生成できるセッション数を制限することでOOM対策をしました。
まとめ
2ヶ月という短い期間でしたが、ネイル画像生成アプリケーションの作成ができました。 既存のデザインだけでなく、複数のデザインの特徴を併せ持つ世界初のデザインのネイル画像を生成できることができました。
今後の展望として、生成したネイルデザインの自分の爪への仮想試着や、ControlNet*8などを用いた手や指の生成などがあります。
最後に、実務訓練を受け入れていただいた株式会社モルフォ及び、ご指導をくださった社員一同に感謝申し上げるとともに、更なる機械学習の発展を望み締め括ります。
最後までお読みいただき誠にありがとうございます。
参考文献
*1:徳力基彦 2023 動画生成AIやアニメ背景生成AIも登場。過熱する生成系AI開発競争の中で考えるべきこと。 https://news.yahoo.co.jp/byline/tokurikimotohiko/20230212-00336730
*2:株式会社プラグ 2022 商品デザインを評価・生成する「パッケージデザインAI」が「第4回 日本サービス大賞」総務大臣賞を受賞 https://prtimes.jp/main/html/rd/p/000000032.000062916.html
*3:GENROQweb編集部 2022「AIがホイールをデザイン?」アウディのデザイン部門が積極的に推し進めるAIによる開発の狙い https://motor-fan.jp/genroq/article/58334/
*4:Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, BjörnHigh-Resolution Image Synthesis with Latent Diffusion Models CVPR 2022
[2112.10752] High-Resolution Image Synthesis with Latent Diffusion Models
*5:Liao, Minghui and Zou, Zhisheng and Wan, Zhaoyi and Yao, Cong and Bai, XiangReal-Time Scene Text Detection with Differentiable Binarization and Adaptive Scale Fusion
*6:Li, Wenbo and Lin, Zhe and Zhou, Kun and Qi, Lu and Wang, Yi and Jia, JiayaMAT: Mask-Aware Transformer for Large Hole Image Inpainting CVPR 2022
[2203.15270] MAT: Mask-Aware Transformer for Large Hole Image Inpainting
*7:Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, StevenBLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
*8:Lvmin Zhang, Maneesh Agrawala Adding Conditional Control to Text-to-Image Diffusion Models
[2302.05543] Adding Conditional Control to Text-to-Image Diffusion Models