こんにちは。CTO室リサーチャーの鈴木です。今回は、深層学習の分野でここ数年盛り上がっているContrastive Learning系の手法について、主だった論文を系統的にまとめて紹介したいと思います。
はじめに
近年発展した自己教師あり学習(Self-Supervised Learning:SSL)は、アノテーション情報を人の手ではなく機械的に付与することで、データセットの構築にかかる時間やコストを軽減し、深層学習モデルの精度向上を目指した手法です。自然言語処理分野におけるSSLは大きな成功を収め、ChatGPT等の超高性能なチャットボットの出現にも影響を与えました。
SSLは主に深層学習モデルの「事前」学習として用いられます。SSLによって、文章や画像に含まれる一般的な特徴を大量のデータから学習することができます。これにより、文章生成や画像認識などの本学習の効率が向上し、最終的な性能向上にもつながります。したがって、SSLは、深層学習において広く使用される重要な技術の1つであると言えます。
今回紹介するContrastive Learning(CL)は、画像処理における代表的なSSLの手法です。データ内で似たもの(正例)と似ていないもの(負例)をグループ化し区別するように学習することで、モデルがより質の高い特徴量を抽出できるようにする手法です。
本記事ではまずCL手法の基本について説明し、その後近年のCL論文28本について、各手法がCLのどの部分を改善したのかに着目して分類し、それぞれの概要を説明いたします。
Contrastive Learning(CL)
多くのCL手法では、ある画像(自身)に2つの異なるオーグメンテーションを加えたもの同士のペアを正例、自身と異なる画像とのペアを負例として学習をします。
初期のCL手法であるNPID(InsDisとも呼ばれます)[1]の概略図を示します(図1)。深層学習モデルを前段の特徴抽出器(backbone)と後段の推論部(head)に分けて考えた時、CLで学習を行うのは主に特徴抽出器の部分(例えばResNet)となります。InsDisでは画像毎に特徴抽出器から得られる128次元の特徴量を用いてCLを行います。また、計算量を増やさず負例の数を増やすために、過去のバッチ内の出力をMemory bankとして記憶しておき、負例として用います。

CLにおける基本の損失関数(InfoNCE損失)は、以下のように表されます(表記は幾つかありますが、ここでは理解しやすいMoCo v2[8]のものを記します)。
式中の はそれぞれ自身・正例・負例の出力特徴量を表します(役割を踏まえ、query、keyと呼ぶこともあります)。内積(cosine類似度)を、正例に対しては大きくし(近づける)、負例に対しては小さくする(遠ざける)損失となっています。正例は自身のオーグメンテーション1つであるのに対し、負例は多数使用するため和をとります。
は学習を制御する温度係数です。
この損失はtriplet lossの拡張として開発されたN-pair loss[2]がベースとなっています。triplet lossでは、自身に似た正例と異なる負例を1つずつ用意し、前者に近づき後者から遠ざかるように学習を行います。CLは負例の数を増やしたtriplet lossとも考えられます。
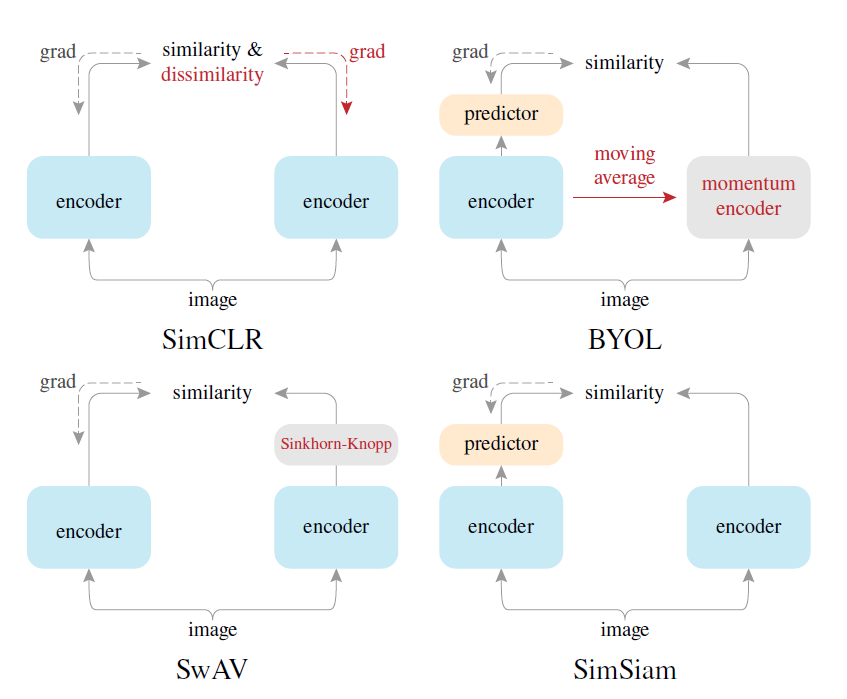
CLの学習機構は、”Siamese(双子の) Network”と呼ばれることもあります。図2に示すように、正例ペアを作る際に同じ構造を持つ(手法によっては完全に同一の)ネットワークを並列にした構造を用いるためです。
CLの現状
画像処理分野のトップカンファレンスであるCVPR(Computer Vision and Pattern Recognition)から、論文タイトル中に"Self-Supervised"や"Contrastive"といった単語を含む論文数を数え上げてみました(図3)。ここ数年でこの2つのキーワードが頻出するようになっており、やはり注目を集めていることが分かります。

下に示すのは、Ce Zhou et al.による”A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT”[3]という、自然言語処理を含む様々なタスクにおける自己教師あり事前学習に関するレビュー論文から引用した、画像における事前学習の主要論文のまとめです(図4)。

CLが流行する以前の自己教師あり学習は、画像を等分し並べ替えるようなタスクや、出力特徴量のクラスタリングとクラスタへの分類を交互に解くようなタスク等、様々な手法が模索されていました。CLは既存の他の手法に大きく勝る精度を残した事で、2020年から大流行しました("Pretext Task"の列が"discrimination"の手法)。2022年はTransformer専用のマスク部分再構成の手法("Pretext Task"の列が"reconstruction"の手法、MAE[4]等)が開発され、発展をしています。
最近ではTransformer専用のCLも開発され、マスク部分再構成の手法と比較しても優れた性能を残しています(Mugs[5]等、Papers With Code[6]にて2023年4月現在Rank 2)。本稿では、CNNかTransformerかという特徴抽出器のアーキテクチャに依存しないCLに焦点を当てて紹介をします。
CLの分類
CLが流行するきっかけになったのは、2020年に発表されたMoCo v1[7]およびSimCLR[10]の論文です。これらの手法は単純な機構で、条件によっては教師あり学習にかなり近い精度を達成したため、一躍話題になりました。その後、これらの手法をベースに、理論的裏付けを検証しつつ精度を向上させる工夫を取り入れた論文が流行し始めたという流れが見られます。
複数の論文を調査する中で、その改善や工夫の方向性に傾向が見えてきましたので、4つのカテゴリに分類して論文をまとめてみました。手法名と、それぞれについての大まかな説明を列挙しています。
1.Collapse(崩壊)せず学習に成功する機構の提案
CLの学習を成功させるための基本的な機構を提案している論文です。後発の論文でもこれらの論文をベースに改善が行われることが多いです。
ところで、CLの学習には全データに対し全く同じ特徴量を出力させるようになる局所解があり、これに陥ると学習が上手くいかなくなります。Collapse(崩壊)と呼ばれるこの現象は各論文でも良く取り上げられ、SimSiam[12]の論文では主題として論じられています。このカテゴリの手法たちは、単なる精度向上だけでなくCollapseを避けるための機構を提案する側面も強いと考えられます。
- MoCo v1[7](2020, CVPR)
- Memory bankに追加される負例の一貫性を高めるため、Momentum encoderというメインの特徴抽出器の重みを徐々にコピーする機構を導入した教師生徒機構を提案。
- SimCLR[10](2020, ICML)
- Memory bankやアーキテクチャ変更が不要のシンプルな機構で高精度なCLを実現すべく、バッチサイズの増大による負例数の増加、最終段に投影用全結合層の導入、最適なオーグメンテーションの組み合わせを検討。
- BYOL[11](2020, NeurIPS)
- 生徒モデルを勾配計算に用いないstop-gradient、教師のみpredictorを持つ非対称な構造を提案し、負例を使わず正例のみで学習可能なCLの機構を提案。
- SimSiam[12](2021, CVPR)
- CLにおけるCollapseの条件について調査し、BYOLでMomentum Encoderを使わずともstop-gradientのみ残せばCLの学習に成功することを確認。
- DINO[13](2021, ICCV)
- Momentum encoder、stop-gradientに、出力特徴量のシャープニングと中央寄せ(それまでの平均値で減算)の処理を加えた構造のCLでCollapseを回避でき、ResNetやVision Transformer(ViT)で高性能であることを確認。
- Barlow Twins[14](2021, ICML)
- 負例、Memory bank、教師生徒機構、stop-gradientを使用しないシンプルな機構で、正例のバッチ方向に対する相互相関行列を単位行列に近づけるような損失関数で学習するCLを提案。
- Self-Classifier[15](2022, ECCV)
- Barlow Twinsと同じくシンプルな機構を目指し、正例ペアの特徴量がの各次元がソフトクラスを表すとみなし、分類問題としてクロスエントロピー損失で学習。Collapseを避けるために一様事前分布で制約した形に損失を修正。
※ 負例を用いないCLにおけるMomentum Encoderの意義
2.正例・負例の改善
これより下は、主に精度改善や汎化を目的とした論文になります。このカテゴリでは、正例や負例に改善を加えることで到達精度を向上を図った論文について、改善の方向性ごとに分けて列挙します。
オーグメンテーションの改善
SimCLRでもCLに対するより良いオーグメンテーションの組み合わせが考察されていますが、定性的な考察によってさらに良いオーグメンテーションを提案した論文です。
- InfoMin[16](2020, NeurIPS)
CLはオーグメンテーション前後の画像間の相互情報量が高過ぎず低すぎない丁度いい時に精度が上がると仮説を立て、それを満たすようなオーグメンテーション戦略を提案。
- C-Crop[18](2022, CVPR)
- オーグメンテーションにおけるクロップの工夫。物体を大きく映すため最終出力ヒートマップの値の高い範囲に限定し、ペアの領域が被らないようにクロップ中心位置が画像端になりやすくする工夫を取り入れたContrastive-Cropを開発。CLでRandom Cropよりも高精度。

正例負例の特徴量を改善
特徴抽出器から出力された正例と負例の特徴量を改善し、精度向上を図る工夫です。一般的なCLは入力画像をオーグメンテーションして比較し学習しますが、それに加え、以下の手法は出力の特徴量もわずかに変化させてから比較して学習するため、「特徴量空間上でのオーグメンテーション」と捉えることもできます。
- AdCo[19](CVPR, 2021)
- 損失の勾配を用いた敵対性学習により、Memory bank内の負例を難しくする方向に更新。
- CaCo[20](2022)
- AdCoに加え、正例については損失の勾配を用いて簡単にする方向に更新することで精度改善。
- FT(Feature Transformation)[21](2021, ICCV)
- 正例はペアとの外挿で更新し離す。負例はMemory bank内でランダムなペアと内挿して更新して多様化させる。
※ CaCoとFTそれぞれの論文で、正例について難しくする(離す)方向、簡単にする(近づける)方向の両方を検証し、逆の結果になっているのが興味深い点です。
「自身以外全て負例」によるFalse Positiveの問題に対処
一般的なCLでは自身のオーグメンテーションのみを正例と扱うため、例えば同じクラスの別の画像は負例として遠ざける方向の学習を行ってしまいます。この部分に問題意識を持ち、正例の選び方を修正した論文です。
- NNCLR[22](2021, ICCV)
- 正例として、自身のオーグメンテーションの代わりにMemory bankで一番近いものを使用。
- ReSSL[23](2021, NeurIPS)
- 正例はMemory bannkから類似したものを選ぶ。学習途中から負例の使用を辞める。Memory bankに追加する正例の一貫性を確保するため、弱いオーグメンテーションを用いる。
- ASCL[24](2022, ICPR)
- Memory bank内のうちcosine類似度の高いものを、類似度を重みとしたソフトな正例として使用。
出力特徴量をクラスタリングしてから利用
一般的なCLでは、個々の画像を負例として使用するため、より汎用的な特徴を学習するには、バッチサイズを増大するかMemory bankを使用するなどの工夫が必要になります。また、上述したように正例のFalse Positiveの問題があります。
この問題を解決するために、出力特徴量をクラスタリングし、学習が進むごとにクラスタの代表値を徐々に更新することで、それをデータ全体の代表値と見なして正例・負例に用いるCLが提唱されています。
- SwAV[25](2020, NeurIPS)
- ランダムな初期値の「プロトタイプ」(出力特徴量と同じ次元のベクトル)を任意の数用意しておき、各出力特徴量をそれぞれ近いプロトタイプに割り振り(クラスタリング)、そのプロトタイプでCLの損失を計算。割り振りの際には特定のクラスへの集中を防ぐため、一様事前分布を仮定。
- PCL[26](2021, ICLR)
- 出力特徴量をK-meansでクラスタリングし、重心に近づく(or離れる)ような損失を設定。複数のKの値を用いて平均の重心を使用。
- SMOG[27](2022, ECCV)
- グループの重心同士ではなく、グループ代表値と個々の値で損失を計算。グループの代表値はmomentumで徐々に更新する。
3.損失項の改善
損失関数に変更を加え精度改善を図った論文です。
- C-BYOL、C-SimCLR[28](2021, NeurIPS)
- 冗長な情報の圧縮を目的とする条件付エントロピーボトルネック(Conditional Entropy Bottleneck; CEB[37])に基づき、出力特徴量そのものではなく、そこから生成したvon Mises-Fisher分布からサンプリングして損失を計算。
- ReLIC v2[29](2022)
- 因果論的解釈に起因する正例のオーグメンテーション前後のKL距離の損失項を加え、先行研究で精度の高かったオーグメンテーションの工夫を取り入れた結果、ImageNetの線形分類で教師あり学習を超えた性能を達成。
4.領域に注目したCL
多くのCLの論文では、ImageNetに対する線形分類で先行研究と性能比較されることが多いです。しかしその性能は、異なるデータセットや下流タスクへの性能の良し悪しとは必ずしも一致しないことが知られています(論文[30]とその解説記事[31]を参照)。特に物体検出や領域分類といった「密な(Dense)」タスクに対する性能との乖離は大きくなっています。また、物体中心(ImageNet, COCO等)ではなくシーン中心(CityScapes等)なデータに対し、画像1枚ずつを比較するというCLのコンセプトが有効であるかは直観的にも懸念があります。
上記の問題を解決するため、画像1枚単位ではなく、画像中の領域単位(特徴抽出器の最終段の画素単位)の特徴量同士でCLを行う手法が開発されています。DenseCLの論文がその出発点です。
- DenseCL[32](2021, CVPR)
- 最終段の投影用の全結合層を1x1畳み込み層に置き換えることで、空間情報を残した領域ごとの出力特徴量によるCLを提案。
- PixPro[33](2021, CVPR)
- 近くの似た画素との滑らかさも学習すべく、他の画素の特徴量とcosine類似度で重みづけ平均したCL。
- SlotCon[34](2022, NeurIPS)
- 画素の特徴量をランダムな初期値で用意されたプロトタイプに割り振り、プロトタイプごとのCL(教師と生徒で同じ番号のプロトタイプは近づけ、それ以外は離す)と、プロトタイプへの分類(教師と生徒で同じ番号のプロトタイプに分類)の2種類の損失で学習。
- RegionCL[35](2022, ECCV)
- クロップした画像を他の画像に貼り付け、元画像領域と貼り付け領域で区別してCL損失に組み込み。
- DenseSiam[36](2022, ECCV)
- SimSiamの構造で領域単位・画素単位のCL損失を計算。
おわりに
近年流行の自己教師あり学習の一つの潮流であるContrastive Learningについて、主だった論文をその概要から系統的にまとめてみました。本稿では個々の論文の詳細については省略しておりますので、気になった点についてはソース元をご覧いただけると幸いです。
出展
[1] Wu, Z., Xiong, Y., Yu, S. X., & Lin, D. (2018). Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3733-3742). Available: https://openaccess.thecvf.com/content_cvpr_2018/papers/Wu_Unsupervised_Feature_Learning_CVPR_2018_paper.pdf
[2] Sohn, K. (2016). Improved deep metric learning with multi-class N-pair loss objective. Advances in neural information processing systems, 29. Available: https://papers.nips.cc/paper/2016/file/6b180037abbebea991d8b1232f8a8ca9-Paper.pdf
[3] Zhou, C., Li, Q., Li, C., Yu, J., Liu, Y., Wang, G., Zhang L., Ji, C., Yan, Q., He, L., Peng, H., Li, J., Wu, J., Liu, Z., Xie, P., Xiong, C., Pei, J., Yu, P. & Sun, L. (2023). A comprehensive survey on pretrained foundation models: A history from BERT to ChatGPT. arXiv preprint arXiv:2302.09419. Available: https://arxiv.org/pdf/2302.09419.pdf
[4] He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16000-16009). Available: https://openaccess.thecvf.com/content/CVPR2022/papers/He_Masked_Autoencoders_Are_Scalable_Vision_Learners_CVPR_2022_paper.pdf
[5] Zhou, P., Zhou, Y., Si, C., Yu, W., Ng, T. K., & Yan, S. (2022). Mugs: A multi-granular self-supervised learning framework. arXiv preprint arXiv:2203.14415. Available: https://arxiv.org/pdf/2203.14415.pdf
[6] "Self-Supervised Image Classification on ImageNet" in Paper With Code. Available: https://paperswithcode.com/sota/self-supervised-image-classification-on
[7] He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9729-9738). Available: https://openaccess.thecvf.com/content_CVPR_2020/papers/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.pdf
[8] Chen, X., Fan, H., Girshick, R., & He, K. (2020). Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297. Available: https://arxiv.org/pdf/2003.04297.pdf
[9] Chen, X., Xie, S., & He, K. (2021). An empirical study of training self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9640-9649). Available: https://openaccess.thecvf.com/content/ICCV2021/papers/Chen_An_Empirical_Study_of_Training_Self-Supervised_Vision_Transformers_ICCV_2021_paper.pdf
[10] Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR. Available: http://proceedings.mlr.press/v119/chen20j/chen20j.pdf
[11] Grill, J. B., Strub, F., Altché, F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Pires, B. A., Guo, Z. D., Azar, M. G., Piot, B., Kavukcuoglu, K., Munos, R. & Valko, M. (2020). Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33, 21271-21284. Available: https://proceedings.neurips.cc/paper/2020/file/f3ada80d5c4ee70142b17b8192b2958e-Paper.pdf
[12] Chen, X., & He, K. (2021). Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 15750-15758). Available: https://openaccess.thecvf.com/content/CVPR2021/papers/Chen_Exploring_Simple_Siamese_Representation_Learning_CVPR_2021_paper.pdf
[13] Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., & Joulin, A. (2021). Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9650-9660). Available: https://openaccess.thecvf.com/content/ICCV2021/papers/Caron_Emerging_Properties_in_Self-Supervised_Vision_Transformers_ICCV_2021_paper.pdf
[14] Zbontar, J., Jing, L., Misra, I., LeCun, Y., & Deny, S. (2021, July). Barlow twins: Self-supervised learning via redundancy reduction. In International Conference on Machine Learning (pp. 12310-12320). PMLR. Available: http://proceedings.mlr.press/v139/zbontar21a/zbontar21a.pdf
[15] Amrani, E., Karlinsky, L., & Bronstein, A. (2022, October). Self-supervised classification network. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXI (pp. 116-132). Cham: Springer Nature Switzerland. Available: https://arxiv.org/pdf/2103.10994.pdf
[16] Tian, Y., Sun, C., Poole, B., Krishnan, D., Schmid, C., & Isola, P. (2020). What makes for good views for contrastive learning?. Advances in neural information processing systems, 33, 6827-6839. Available: https://proceedings.neurips.cc/paper/2020/file/4c2e5eaae9152079b9e95845750bb9ab-Paper.pdf
[17] Google Research Blog, Posted by Yonglong Tian, Student Researcher and Chen Sun, Staff Research Scientist, Google Research, on FRIDAY, AUGUST 21, 2020. Available: https://ai.googleblog.com/2020/08/understanding-view-selection-for.html
[18] Peng, X., Wang, K., Zhu, Z., Wang, M., & You, Y. (2022). Crafting better contrastive views for siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16031-16040). Available: https://openaccess.thecvf.com/content/CVPR2022/papers/Peng_Crafting_Better_Contrastive_Views_for_Siamese_Representation_Learning_CVPR_2022_paper.pdf
[19] Hu, Q., Wang, X., Hu, W., & Qi, G. J. (2021). Adco: Adversarial contrast for efficient learning of unsupervised representations from self-trained negative adversaries. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1074-1083). Available: https://openaccess.thecvf.com/content/CVPR2021/papers/Hu_AdCo_Adversarial_Contrast_for_Efficient_Learning_of_Unsupervised_Representations_From_CVPR_2021_paper.pdf
[20] Wang, X., Huang, Y., Zeng, D., & Qi, G. J. (2022). Caco: Both positive and negative samples are directly learnable via cooperative-adversarial contrastive learning. arXiv preprint arXiv:2203.14370. Available: https://arxiv.org/pdf/2203.14370
[21] Zhu, R., Zhao, B., Liu, J., Sun, Z., & Chen, C. W. (2021). Improving contrastive learning by visualizing feature transformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 10306-10315). Available: https://openaccess.thecvf.com/content/ICCV2021/papers/Zhu_Improving_Contrastive_Learning_by_Visualizing_Feature_Transformation_ICCV_2021_paper.pdf
[22] Dwibedi, D., Aytar, Y., Tompson, J., Sermanet, P., & Zisserman, A. (2021). With a little help from my friends: Nearest-neighbor contrastive learning of visual representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 9588-9597). Available: https://openaccess.thecvf.com/content/ICCV2021/papers/Dwibedi_With_a_Little_Help_From_My_Friends_Nearest-Neighbor_Contrastive_Learning_ICCV_2021_paper.pdf
[23] Zheng, M., You, S., Wang, F., Qian, C., Zhang, C., Wang, X., & Xu, C. (2021). Ressl: Relational self-supervised learning with weak augmentation. Advances in Neural Information Processing Systems, 34, 2543-2555. Available: https://proceedings.neurips.cc/paper/2021/file/14c4f36143b4b09cbc320d7c95a50ee7-Paper.pdf
[24] Feng, C., & Patras, I. (2022, August). Adaptive Soft Contrastive Learning. In 2022 26th International Conference on Pattern Recognition (ICPR) (pp. 2721-2727). IEEE. Available: https://arxiv.org/pdf/2207.11163.pdf
[25] Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., & Joulin, A. (2020). Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33, 9912-9924. Available: https://proceedings.neurips.cc/paper/2020/file/70feb62b69f16e0238f741fab228fec2-Paper.pdf
[26] Li, J., Zhou, P., Xiong, C., & Hoi, S. C. (2020). Prototypical contrastive learning of unsupervised representations. arXiv preprint arXiv:2005.04966. Available: https://arxiv.org/pdf/2005.04966.pdf
[27] Pang, B., Zhang, Y., Li, Y., Cai, J., & Lu, C. (2022, November). Unsupervised Visual Representation Learning by Synchronous Momentum Grouping. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXX (pp. 265-282). Cham: Springer Nature Switzerland. Available: https://arxiv.org/pdf/2207.06167.pdf
[28] Lee, K. H., Arnab, A., Guadarrama, S., Canny, J., & Fischer, I. (2021). Compressive visual representations. Advances in Neural Information Processing Systems, 34, 19538-19552. Available: https://proceedings.neurips.cc/paper/2021/file/a29a5ba2cb7bdeabba22de8c83321b46-Paper.pdf
[29] Tomasev, N., Bica, I., McWilliams, B., Buesing, L., Pascanu, R., Blundell, C., & Mitrovic, J. (2022). Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?. arXiv preprint arXiv:2201.05119. Available: https://arxiv.org/pdf/2201.05119
[30] Ericsson, L., Gouk, H., & Hospedales, T. M. (2021). How well do self-supervised models transfer?. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 5414-5423). Available: https://openaccess.thecvf.com/content/CVPR2021/papers/Ericsson_How_Well_Do_Self-Supervised_Models_Transfer_CVPR_2021_paper.pdf
[31] AI-SCHOLAR, 2021年11月09日, "Self-Supervisedモデルは下流タスクでどれだけ成功するか?" Available: https://ai-scholar.tech/articles/self-supervised-learning/SSLModels
[32] Wang, X., Zhang, R., Shen, C., Kong, T., & Li, L. (2021). Dense contrastive learning for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3024-3033). Available: https://openaccess.thecvf.com/content/CVPR2021/papers/Wang_Dense_Contrastive_Learning_for_Self-Supervised_Visual_Pre-Training_CVPR_2021_paper.pdf
[33] Xie, Z., Lin, Y., Zhang, Z., Cao, Y., Lin, S., & Hu, H. (2021). Propagate yourself: Exploring pixel-level consistency for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16684-16693). Available: https://openaccess.thecvf.com/content/CVPR2021/papers/Xie_Propagate_Yourself_Exploring_Pixel-Level_Consistency_for_Unsupervised_Visual_Representation_Learning_CVPR_2021_paper.pdf
[34] Wen, X., Zhao, B., Zheng, A., Zhang, X., & Qi, X. (2022). Self-supervised visual representation learning with semantic grouping. arXiv preprint arXiv:2205.15288. Available: https://arxiv.org/pdf/2205.15288.pdf
[35] Xu, Y., Zhang, Q., Zhang, J., & Tao, D. (2022, November). RegionCL: Exploring Contrastive Region Pairs for Self-supervised Representation Learning. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIII (pp. 477-494). Cham: Springer Nature Switzerland. Available: https://www.ecva.net/papers/eccv_2022/papers_ECCV/papers/136930468.pdf
[36] Zhang, W., Pang, J., Chen, K., & Loy, C. C. (2022, November). Dense Siamese Network for Dense Unsupervised Learning. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXX (pp. 464-480). Cham: Springer Nature Switzerland. Available: https://arxiv.org/pdf/2203.11075.pdf
[37] Fischer, I. (2020). The conditional entropy bottleneck. Entropy, 22(9), 999. Available: https://www.mdpi.com/1099-4300/22/9/999