はじめまして。株式会社モルフォのソフトウェアエンジニア、神谷と申します。
前回に引き続き、withコロナ時代の社会貢献として当社が考えたアイデア
- 手で顔を触ったことを判定し、教えてくれる機能
- オンライン会議中に、しゃべっていないときは自動でマイクをミュートする機能
のうち、2つめのアイデアについて紹介します。なお前回の記事は こちら です。
開発の背景
新型コロナウイルス感染拡大の影響でオンライン会議が増えた方は多いのではないでしょうか。私もその1人です。大勢の人が参加するオンライン会議で、下記のような経験はないでしょうか。
- 常にマイクをONにしており、キーボードのタッチ音等のノイズが相手に聞こえてしまっていた
- 発言しないときにマイクをOFFにしていたら、いざ発言する際にマイクをONにするのを忘れてしまい相手に聞こえていなかった
- マイクの ON/OFF に気をつけているが、手動の操作が煩わしい
本アイデアはこれらの経験をもとに生まれました。今、発話しているかしていないかを判定し、その判定に基づいて自動でマイクのON/OFFを切り替えてくれる機能があればオンライン会議の利便性が向上するだろう、そんな考えをもとに今回の開発がスタートしました。
開発の概要
本アイデアを実現するためのシステムとして、図1のようなシステムを考えました。
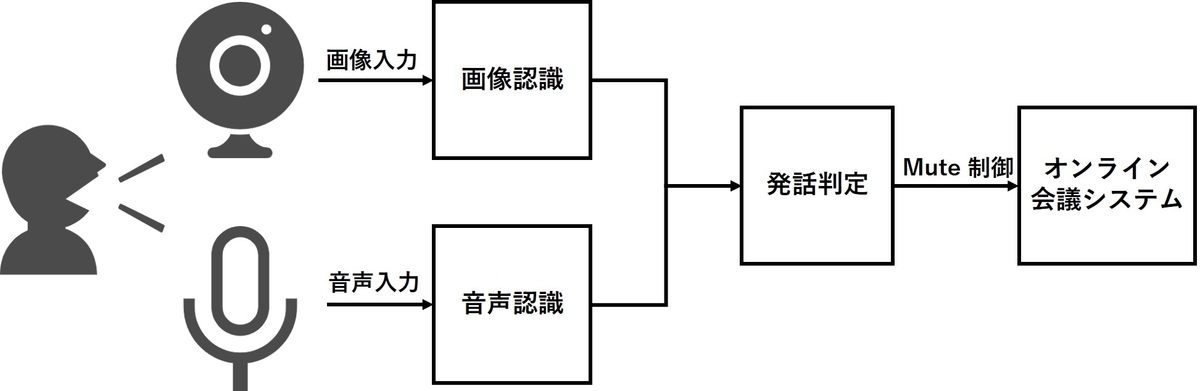
当社ではオンライン会議システムに Google Meet を標準的に利用しており、今回の開発ではこの Google Meet を開発ターゲットに選定しました。 また開発方針を検討する際に、本機能を多くの人に使ってもらうことを考えた場合にブラウザの拡張機能として動くものであればインストールのハードルが低いと考えブラウザの拡張機能 (Chrome Extension) として開発することにしました。Chrome Extension の開発方法については Google 公式ページ で JavaScript を用いた開発方法についてチュートリアルがあるため開発の障壁も高くありません。
以下、それぞれの開発要素について紹介します。
画像認識による判定
まず画像認識による発話判定として、口の開閉判定を行うことを考えます。口の開閉判定を行うためには、顔の検出および口の検出を行う必要があります。今回は JavaScript 上で動く顔検出ライブラリとして、MIT ライセンスで公開されている下記の face-api.js を用いています。
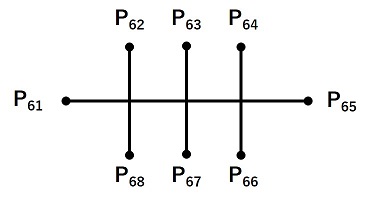
図2に示される通り、face-api.js には68点の顔特徴点を抽出するモデルがあり、これら特徴点を利用して口の開閉判定を行います。図の49番から68番までの点が口の座標に対応しているため、これらの座標を用いて何らかの指標を定義し、口の開閉判定を行うことを考えます。
出典:iBUG: facial point annotations Figure 2 より引用 図2.顔の68点の特徴点

口の開閉判定に用いる指標としては、口の縦横比として下記のサイトで紹介されている MAR (Mouth Aspect Ratio) というアイデアを参考にしています。
このサイトで紹介されている MAR の定義では、唇の外側の座標が使われています。しかし同じ定義の MAR を用いようとすると唇の厚さは個人差が大きいことから、本開発に上手く適用することができませんでした。そこで本開発では唇の内側の座標として図3に示した から
までの8点を用いることにし、式1で定義される MAR を使用します。
この MAR がある閾値以上であれば口が開いていると判定し、閾値未満の場合は口が閉じていると判定します。図4はこのアルゴリズムによって口の開閉判定を行っている例です。MAR の閾値は0.4としています。

以上により口の開閉判定が行えるようになりましたが、口の開閉判定と発話判定を等価にしてしまうと少し口を閉じただけで頻繁にマイクがOFF(自動ミュート)になってしまい、実用上は好ましくありません。そこで口が開くと即座にマイクがONになるが、マイクをOFFにするには一定時間(例えば約1秒)口を閉じ続けることを条件としています。
音声認識による判定
次に、音声認識による発話判定について紹介します。画像認識による判定のみではマスク等で口が隠れている場合に判定できなくなってしまうため、音声認識も併用することを考えます。ただし単純に音が発生しているときにマイクをONにするのでは発話以外のノイズにも反応してしまいます。つまり人間が喋っている音声とノイズを明確に区別する必要があります。そこで音声認識によって音声が言葉として認識できたかどうかを判定基準としています。
今回は JavaScript で音声認識を行うにあたって Web Speech API の Speech Recognition 機能を利用しています。Web Speech API は W3C コミュニティグループによって策定されている音声関連機能の仕様で、対応しているブラウザは限定的ですが、今回の開発対象である Chrome には対応しています。
SpeechRecognition の API にある onresult というプロパティが、音声を言葉として認識できた際に発火するイベントハンドラです。そのため下記のように、音声を言葉として認識できた際に実行したい処理を記述することができます。
const recognition = new SpeechRecognition();
...
recognition.onresult = function(event) {
...
音声を言葉として認識できた際に実行したい処理
...
}
音声認識による発話判定では、onresult によるイベントハンドラの発火でマイクONになるようにしています。
発話判定とミュート制御
最後に、最終的な発話判定とミュート制御部分について紹介します。
まず最終的な発話判定ですが、画像認識による発話判定と音声認識による発話判定の OR 条件としています。これは画像認識による判定も音声認識による判定もどちらも精度が100%ではなく、相補的なものであると考えたためです。
ミュート制御部分についてですが、Google Meet 上でのミュート制御(マイクの ON/OFF 制御)には Windows では Ctrl+d のショートカットキーが割り当てられているためこれを利用します。JavaScript 上の記述で、仮想的に Ctrl+d のキーダウンイベントを発生させるようにしています。具体的なコードについては MIT ライセンスで公開されている下記の Google-Meet-Mute-Toggler を利用しています。
ただし、Ctrl+d による制御はトグル制御(一度押すとミュート状態になり、もう一度押すと元に戻る)ですので、スクリプトによる Ctrl+d 制御と実際のユーザー手動による Ctrl+d 制御が混在してしまうと、意図せずトグル状態が反転してしまうことがありました。そのため、実際のコードではまず現在ミュート状態かどうかを確認してから意図する方向に制御するようにしています。
以上により、画像認識と音声認識による発話判定の結果から自動ミュート制御するシステムを作ることができました。

最後に
今回ご紹介した自動ミュート機能の Chrome 拡張は、下記 Chrome ウェブストアにて公開しています。Chrome とウェブカメラ・マイクがあれば簡単に試すことができますので興味のある方はぜひ一度試してみてください。
またソースコードも GitHub にて公開しています。
当社には画像処理と機械学習を専門としたソフトウェアエンジニアが数多く在籍しています。「画像処理を用いて課題を解決したい!」「AIで社会貢献したい!」こういった要望がありましたらお気軽にお問い合わせください。