こんにちは。CTO室リサーチャーの芳賀です。
論文紹介
前編に引き続き CVPR 2020 にて私が注目した研究について紹介をしたいと思います。
Correction Filter for Single Image Super-Resolution: Robustifying Off-the-Shelf Deep Super-Resolvers
Author: Shady Abu Hussein, Tom Tirer, Raja Giryes.
単一画像超解像 (SISR: Single Image Super Resolution) に関する話題で、既存の超解像モデルのパフォーマンスを向上させる補正フィルタの論文です。
昨今の超解像技術はどんどん進歩していますが、超解像モデル の出力画像の品質が実用段階で劣化してしまう問題があります。
その主な原因として、ダウンサンプラ
のメカニズム (カーネル
) が学習時とテスト時に異なる点に注目しています*1。
本論文では異なるカーネルのLR (Low Resolution) 画像
をネットワークに入れる前に、カーネルの違いを補正するフィルタ
をかけることで出力の品質が向上することを示しています。

本論文の新規性としては、既存の超解像DNNモデルをpre trainなしにそのまま使えることや、カーネルの種類に制限がないことが挙げられます。 また実用時のカーネルに関して2種類の問題設定を用意しています。
1つ目は のカーネル
が既知とする「non-blind」ケースです。
この場合は解析的に解くことができ、補正フィルタ
として離散フーリ変換を定義することができます。
2つ目は のカーネル
が未知とする「blind」ケースで、現実はこちらのケースがほとんどでしょう。
この場合は、補正フィルタ
を複数のCNNで構成し目的関数を用いてパラメータを最適化します。
CNNは4レイヤーで構成されており、カーネルサイズは前段3つが33×33、最終層が32×32となっています。
出力結果は下図のようになっていて、non-blindケース、blindケースともに補正フィルタを入れることで既存のSISRモデルの出力が劇的に向上しています。 本論文はCVPR 2020 AWARDにおけるノミネート論文となっており、超解像の品質向上に対するアプローチやどんなSISRモデルでも適用できるといった点が評価されたのではと感じました。


Fast Soft Color Segmentation
Author: Naofumi Akimoto, Huachun Zhu, Yanghua Jin, Yoshimitsu Aoki.
下図のように一枚のRGB画像から色ごとの複数のRGBAレイヤーに分割する手法に関する論文です。

反復的なアルゴリズムで解く従来手法*2がありましたが、本研究ではDNNを組み込むことで出力の高速化・高精度化を果たしています。 学習はSelf-Supervisedで、処理の流れは下図のように3段階に分けられます。
- Kmeas法を用いたレイヤーに分割する色の推定
- 各分割色のアルファレイヤー推定
- 各分割色のRGBレイヤー推定

最後のRGBレイヤーですが、分割色 (本論文では7色固定) とアルファレイヤーの合成だけでは元の画像を完全に復元できないため、元画像との残差分の色情報を推定して含めたものになっています。 そのため学習時のロスとしては、
- RGBAレイヤー (残差込み) の再構成誤差 (図:
)
- 分割色とアルファレイヤーのみによる再構成誤差 (図:
)
- アルファレイヤーを考慮したRGBレイヤーと分割色の差異 (図:
)
の3つを用意して学習を進めています。
出力画像の分離精度も向上したことに加えて、処理速度は従来手法の30万倍と大きな高速化を実現しております。 1080p解像度で12GBのGPUメモリを必要とする制約はありますが、色レイヤーごとに画像処理を施したりと応用の幅が広く面白い研究だと感じました。
BEDSR-Net: A Deep Shadow Removal Network From a Single Document Image
Author: Yun-Hsuan Lin, Wen-Chin Chen, Yung-Yu Chuang.
文書の影除去に関する論文です。 自然画像における影除去はDNNベースの手法が発展していますが、文書画像に適用する際は (文書画像で訓練したとしても) 品質が良くないと述べています。 一方で文書画像に特化した影除去の手法は文書の背景部の色を推定し影を除去するアプローチがありますが、影の境界部の除去がイマイチだったり大部分が影に覆われているケースで失敗してしまうデメリットがありました。
本論文では下図のようにDNNベースのアルゴリズムを考案しています。 まずBE-Netと呼ばれるネットワークで背景部分のRGB色推定と影のAttention Map推定を行います。 次にSR-Netと呼ばれるネットワークで上記2つの出力からGANベースで最終的な影除去画像を得る流れになっています。
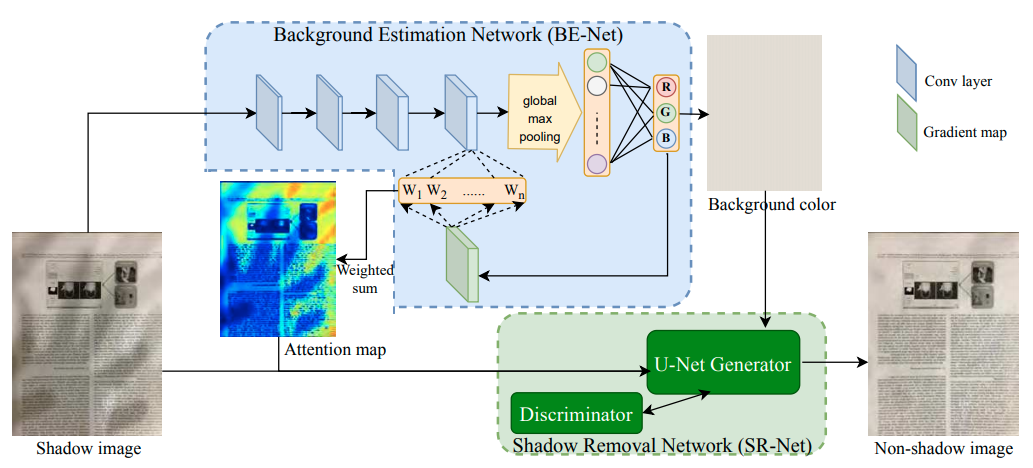
本手法のメリットとしてはBE-Netにより影のAttention Mapを作るため、影のアノテーションが必要ないことが挙げられます。 また文書影除去に対する既存のデータセットは少ないため、学習に使用するデータとしては3Dモデリングツールを用いて8309件ものサンプルを作ったとのことです。
結果は下図のようになっていて、広範囲に影が覆われたもの・影が重なっているケースについても非常にキレイに除去できていることがわかります。 また、生成画像の文書の可読性をOCRツールにかけた際のLevenshtein距離で測っていて、従来手法を超える結果を達成したことを示しています。 一度に影除去画像を生成するのではなく、背景色と影のMapとを中間生成物として活用する点がうまいと感じた研究でした。

Visual Chirality
Author: Zhiqiu Lin, Jin Sun, Abe Davis, Noah Snavely.
自然画像の左右対称性に関する学習への影響を調査した論文です。 Visual Chiralityとは「画像を鏡映対称と仮定したときの近似誤差」と本論文で定義しています。 具体例としては、画像データセット中の「親指を上げた手」を考えたとき右手と左手とで頻度に違いが生じます(親指を上げるという行為は右手で行うケースがほとんどのため)。 Deep Learningによる学習でこのようなVisual Chiralityを調査したことが論文の主旨になります。
論文では入力画像が左右反転しているかしてないかを判別するSelf-Supervised Learningを用いて調べています。 また、Class Activation Map (CAM) を用いて画像中のどの部分から反転を判断しているか可視化する実験をしました。
論文では2種類のCAMのActivationについて論じています。
- 画像処理由来のActivation:Bayerデモザイキング、JPEG圧縮
- 一般の物体由来のActivation:文字、腕時計、襟、顔のパーツ等
1つ目はBayerデモザイキングとJPEG圧縮といったLow-levelな画像処理がVisual Chiralityに影響を与えていることを示しています。 結果を簡潔にまとめるとBayerデモザイキングとJPEG圧縮を組み合わせると、Random Croppingを入れても入れなくてもDeep Learningによって左右反転判別が可能であることが示されました*3。 詳細は論文のSupplementパートに論じられています。
2つ目は人間が左右反転を識別できるようなHigh-levelな特徴を、Deep Learningも注目していることが示されました。 具体的なCAM出力結果は以下の図になっていて、たしかにスマートホンを持つ手、ギターの持ち手、腕時計・襟やポケットの位置といった部分にActivationが集中していることがわかります。

本論文はCVPR 2020 AWARDにノミネートされています。 発表動画は非常に作り込まれていてインパクトがあり、同時に興味深い研究だと感じました。
全体の感想
画像処理系の国際学会への参加は初めてでしたが、CV分野における昨今の課題感から技術まで広く学ぶことができました。 従来手法のどの問題点に注目しどういう改善をしたかというアプローチを理解することが、それぞれの研究を読み解く上で非常に大事だなと感じました。 またバーチャル開催ということで不安はありましたが、前撮りの動画やZoom会議の場合は録画したものをアップロードしてくれる配慮が徹底されていて、時差が異なる地域からも通常の活動時間帯で参加できたのもよかったです。
モルフォでは引き続き最新技術のキャッチアップを行い、価値ある製品の開発に取り組んで参ります。
参考文献
[1] Shady Abu Hussein, Tom Tirer, and Raja Giryes. Correction Filter for Single Image Super-Resolution: Robustifying Off-the-Shelf Deep Super-Resolvers. In Proc. CVPR 2020.
[2] Naofumi Akimoto, Huachun Zhu, Yanghua Jin, and Yoshimitsu Aoki. Fast Soft Color Segmentation. In Proc. CVPR 2020.
[3] Yun-Hsuan Lin, Wen-Chin Chen, and Yung-Yu Chuang. BEDSR-Net: A Deep Shadow Removal Network From a Single Document Image. In Proc. CVPR 2020.
[4] Zhiqiu Lin, Jin Sun, Abe Davis, and Noah Snavely. Visual Chirality. CVPR 2020.
*1:例えば、バイキュービック縮小 によるLR (Low Resolution) 画像を用いて超解像モデルを学習させた場合、ガウスカーネル
によるLR画像をそのモデルで超解像しても期待の精度が得られない。
*2:Yagiz Aksoy, Tunc Ozan Aydin, Aljoscha Smolic and Marc Pollefeys. Unmixing-based soft color segmentation for image manipulation. ACM Transactions on Graphics (TOG), 2017
*3:実験での入力はランダムノイズ画像を用いていて、Bayerデモザイキング・JPEG圧縮・Random Croppingの組み合わせについて検証している。