Hi everyone! I am Chamin, a boffin researcher from Morpho's CTO Office. As members of Morpho's main R&D division, we regularly attend conferences on Computer Vision and Machine Learning. This helps us to keep in touch with the state of the art, and also gain insights to new research topics. So, one (sometimes a few) of us would attend a conference, summarize the interesting stuff, and share them with the colleagues.
ICIP 2020 - The 2020 International Conference on Computational Photography - was supposed to be held in St. Louis, USA. However, due to COVID-19 concerns, it was conducted as an online event. In this post, I will summarize a few interesting papers from this conference.
In Computational Photography, we investigate digital processing techniques that can replace or supplement optical processes that are used in taking pictures. Admittedly, that sounds more like rocket science than photography, so let me give you an example. Suppose you want to have a good bokeh effect in photos that you take with your smartphone. If you rely solely on optics to do this, you will end up with a thick phone that has a HUGE lens (expensive, hard to carry and maintain, etc.). Instead, the present-day smartphones use a couple of tiny cameras, other sensors, and computational photography techniques to provide a similar effect. Figure 0 is an example for such a photo, taken with an iPhone 11 Pro.

OK, so much for the introduction. The following are four of about a dozen ICCP 2020 papers that I summarized and shared with my colleagues. I hope you'll find them interesting.
Deep Slow Motion Video Reconstruction with Hybrid Imaging System
Paliwal et al. (PDF)
Problem
Slow motion videos are gaining popularity, particularly in social media, with the emergence of new smartphones that can capture video at high frame rates. Typically, a slow motion video is created by capturing video at a frame rate much higher than 30 frames per second (iPhone 11, for example, can capture at 240 fps) then playing it back at 30 frames per second. Not all cameras are capable of recording at such high frame rates, though. In such cases, intermediate frames can be created using software to create slow motion images. However, this requires estimating missing information, and is a challenging task when complex movements are present in the scene. By the way, we have done this at Morpho and you can see a demo here.
Approach
The authors suggest a dual camera-based approach for creating slow motion video with better quality. Dual or multiple camera systems are getting increasingly common in mobile phones. They can be used for a wide variety of purposes, as surveyed here. The authors suggest using one camera to capture a high resolution video with a low frame rate. The other camera captures a low resolution, high frame rate video. The hypothesis of this paper is that by combining these two videos, a high resolution, high frame rate video can be constructed. The end result is a high resolution slow motion video.
Fig. 5 in Ref. [1] presents a functional overview of the proposed approach. All three stages of processing use Deep Neural Networks (I bet you could see that coming). Frames of the high-resolution video are referred to as keyframes, whereas frames of the low-resolution video are called auxiliary frames.

The first two stages are called "alignment tasks". In the first stage, the auxiliary frames are used to calculate the initial optical flow between the target and neighboring frames. Using the optical flow, a given keyframe can be warped to create intermediate frames. The second stage adds information from the keyframes to improve these intermediate frames. Fig. 6 in Ref. [1] illustrates how the two-stage process improves the video quality when moving objects are present in the scene.

In the final state named appearance estimation a context and occlusion-aware CNN is used to combine warped frames and target auxiliary frames to produce the final, high resolution frames. Using visibility masks created with the auxiliary frames, the authors manage to remove ghost-like effects in the resulting high resolution frames (Fig. 8 in Ref. [1], around the ball).

The authors train this system in an end-to-end fashion by minimizing the loss between the synthesized and ground truth frames on a set of training videos. For training data, they use a set of high frame rate videos with high resolution as the ground truth, and propose an approach to synthetically generate the main and auxiliary input videos, emulating the inputs from two real cameras with a small baseline.
Data
For training the DNNs, authors used a dataset of 875 video clips that they synthesized by editing Youtube videos (I suppose they also watched a lot of cat videos during this process :-p). They also used the Adobe-240fps dataset for training.
Results
The authors evaluate the performance of this approach by evaluating it on Slow Flow, Middlebury and NfS datasets. They compare the accuracy measures LPIPS and SSIM with those obtained using related approaches (namely DAIN, DUF, EDVR and Super Slo Mo). The proposed approach produces results that are better than all other approaches.
The authors do not mention the processing time of their algorithms. While they did test their approach on video captured with a mobile phone, they did not execute the algorithms within the phone. Judging by the network architecture and descriptions, this seems computationally expensive. So, don't rush to make an app with this just yet :o).
Unveiling Optical Properties in Underwater Images
Bekerman et al. (Video presentation)
Problem
While underwater photography is a relatively less common photographic activity, it is a challenging task to capture high quality underwater photos even for professional photographers with good equipment. A combination of Low contrast, color cast, blurriness and noise result in photos that are low in clarity. The photo quality also deteriorates with distance, making it harder to make automatic refinements. Fig. A in Ref. [2] is an example underwater photograph from this paper.

Approach
With the emphasis on restoring the colors of the image to match those of the scene, the authors take a physics based approach to solve this problem (Fig. B in Ref. [2]).
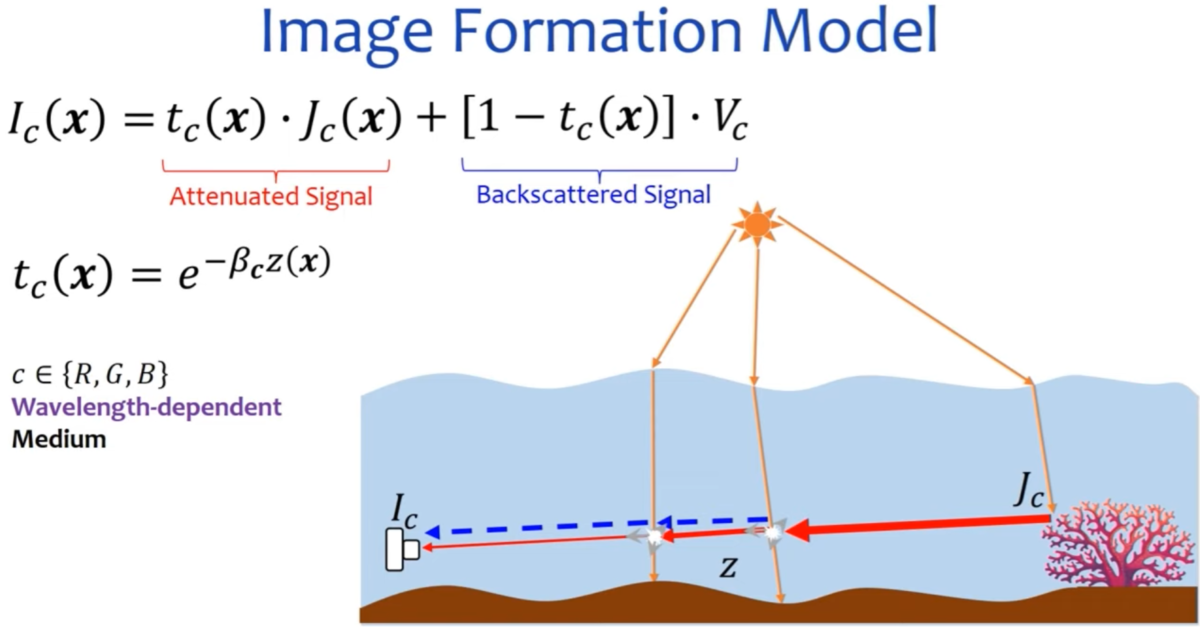
The main steps in this approach are:
- Global white balance/ambient light correction: performed using known optical properties of sea water
- Attenuation coefficient estimation
- Veiling light estimation
- Restore the image using the above parameters and haze lines (previously developed approach)
The authors' main contribution lies in steps 2 and 3. Haze-lines is a technique designed for images captured on land, and cannot be directly used on underwater images. The authors propose a log-projection based approach to estimate haze curves and then convert them to haze lines.
Veiling light - light that does not originate from the objects themselves but end up reaching the focal plane - are filtered out using an iterative method. Like in many previous works, the authors first estimate veiling light from the background of the scene. However, they further refine it using nearby regions. According to the authors, this improves the accuracy of the estimation.
Data
The authors use SQUID dataset to evaluate the proposed method and also to compare it with other approaches. The stereo information in the dataset have not been used.
Results
The results seem much better than the other works in the comparison. The Macbeth-like color charts placed in the scene have been used for quantitative evaluation of color reconstruction error. The proposed approach results in the lowest color reconstruction error, out of the approaches that have been compared.
Fig. C in Ref. [2] and Fig. D in Ref. [2] demonstrate how a photo taken at a 20 m depth has been reconstructed. It is evident that details at higher depths have been recovered well, with few artifacts.


NLDNet++: A Physics Based Single Image Dehazing Network
Tal et al. video presentation
Problem
Removing haze from a digital photo is a challenging task because the effect of haze varies with distance, and also causes loss of information where fine details are present at large distances from the camera. While several researches have been published, there still is a lot of room for improvement.
Approach
The authors propose using a Physics-based model for haze, as shown in Fig. A in Ref. [3] (note the similarity to the model in the previous paper). You can see that the light entering the eye (or camera) is a combination of object irradiance (light actually reflected/emitted by the object) and scattered air-light. Given that many of the related parameters are unknown during image capture, obtaining a haze free image using this model is an ill-posed problem.
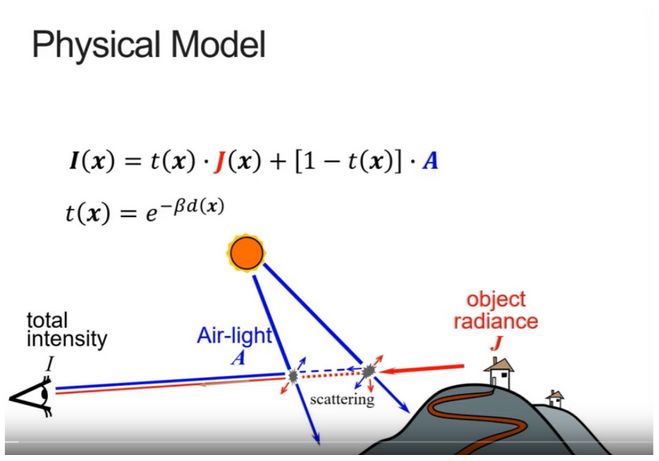
A common approach to image dehazing based on the above model is NLD(Non Local Dehazing). pixels from a small color palette are sampled from different regions of the image, and their variations are used for estimating the model parameters. However, this approach is inherently noisy because of working with non-localized pixels. The authors propose a few modifications to NLD (hence the name NLD++) for improved results.
First, the authors apply a technique called BM3D (Block Matching 3D Filtering) to preprocess images before dehazing. Second, they apply lower bound constraints to the transmission mapping (denoted as t(x) in Fig. A in Ref. [3]). Third, they use a least-square optimization algorithm for estimating t(x).
While the above modifications improve the image quality, they have a high computational cost. To solve this problem, the authors resort to (surprise, surprise) DNNs. They use NLD++ to create "Pseudo Ground Truth" from hazy images and then train a Convolutional Deep Neural Network with it. While CNNs, too, are computationally intensive, the ability to use GPUs make them comparatively faster than the NLD++ calculations on CPU.
Data
The autors use SOTS, HazeRD (two synthesized haze image datasets based on NLD++), and OHazy dataset for training and evaluation. The synthesized datasets are relatively small, with only 4000 images in them. Because of this limitation, the author also try taking a pre-trained dehazing network (GridDehazeNet) and fine-tuning it using the synthesized data.
Results
The authors compare the proposed approach with Detailed results on the video presentation show that NLD++, and NLD++ together with GridDehazeNet provides the best PSNR among the approaches compared. Upon subjective evaluation, my opinion is that the improvement seems to depend on the image.

Photosequencing of Motion Blur using Short and Long Exposures
Rengarajan et al. PDF
Problem
Photosequencing is the process of creating a sequence of sharp photos from one photo that contains motion blur. Fig. 1 in Ref. [4] shows an example blurry photograph. This video plays the sequence of sharp photos created using this single blurry image (impressive, huh?). The ability to perform accurate photosequencing is very useful, because photos can be captured with long exposures at low light situations and then processed later to create a sharp image sequence.
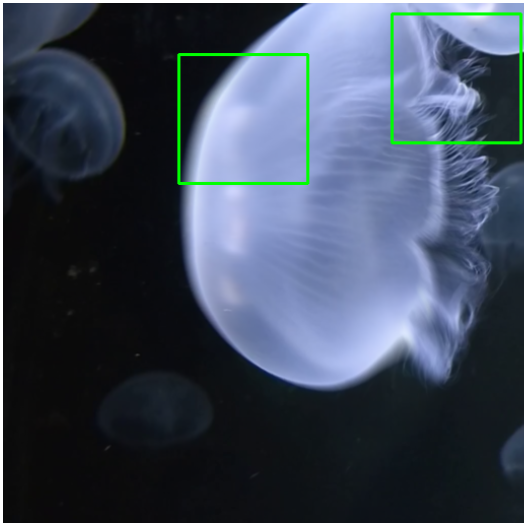
However, this is an extremely challenging task, particularly if the movement is non-rigid.
Approach
The authors suggest using three photos, instead of one. Two short-exposure photos are captured before and after the blurry, long exposure photo (Fig. 1 in Ref. [4]). While these two photos are noisy, they provide valuable information regarding the initial and final positions of the moving objects. These three images are then fed into a U-Net like DNN that provides three intermediate frames as output (Fig. 3 in Ref. [4]). These frames are sharp, and can be used as part of the photosequence. By recursively feeding these outputs back to the network, a photosequence with a larger number of images can be created.

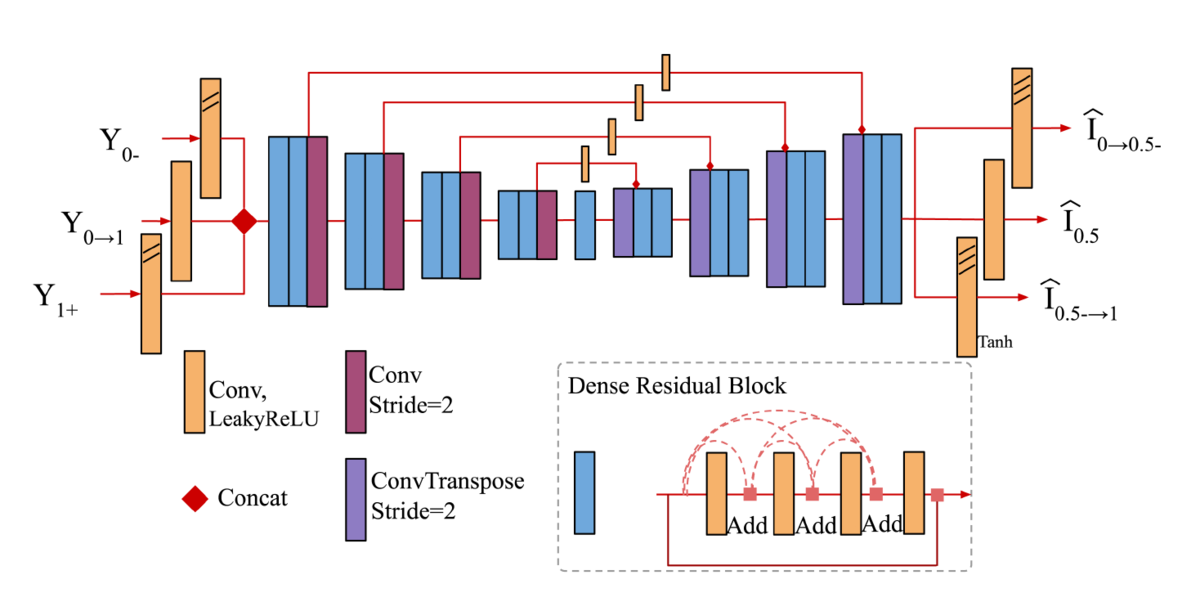
Data
The authors trained the DNN with images extracted/synthesized from the 240 fps datasets shared by Sony, GoPro and Adobe.
Results
The video linked above shows an example photosequence created using the proposed method. The results are visually pleasing. Other results on the paper indicate some artifacts with more complicated motions. Comparisons with two related works show that sequences created using the proposed method have higher PSNR.
Comments
I like how the authors approach the problem by breaking it into parts; modifying the capture process by taking two extra photos, and then feeding all three photos to a DNN. The more common approach is to feed a single photo into the DNN to do everything. That is much easier to start with, but also much less likely to produce good results.
Concluding remarks
Phew. That was long. But I assume that you skipped or glossed over the papers that did not interest you, and had a closer look at the others. I have provided links to papers that are available online for free, for those who want more details. I also deliberately avoided re-listing references from the original papers, for brevity.
Since I attended the conference online and did not purchase the proceedings, I had to use screenshots of the videos for some figures. Pardon me if you have complaints about the quality of figures m(_ _)m.
One more thing before I wind up. This is an academic conference, so don't expect that you can pick a paper from here, make stuff using its ideas, sell them and get rich. Research papers show you a direction and give you credible hints on where you can end up. You still have a long way to go, though, before you get there. At Morpho, both researchers and interns take such journeys to contribute to great imaging products. If that sounds interesting to you, we are hiring (^_~) .
References
[1] A. Paliwal and N. Khademi Kalantari, "Deep Slow Motion Video Reconstruction with Hybrid Imaging System," IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
[2] Y. Bekerman, S. Avidan and T. Treibitz, "Unveiling Optical Properties in Underwater Images," Video presentation on https://www.youtube.com/watch?v=QqPmPeiuqtY&feature=youtu.be, IEEE International Conference on Computational Photography (ICCP), 2020.
[3] I. Tal, Y. Bekerman, A. Mor, L. Knafo, J. Alon and S. Avidan, "NLDNet++: A Physics Based Single Image Dehazing Network," Video presentation on https://www.youtube.com/watch? v=QqPmPeiuqtY&feature=youtu.be, IEEE International Conference on Computational Photography (ICCP), 2020.
[4] V. Rengarajan, S. Zhao, R. Zhen, J. Glotzbach, H. Sheikh, and A. C. Sankaranarayanan, “Photosequencing of motion blur using short and long exposures,” arXiv preprint arXiv:1912.06102, 2019.